Add initial documentation and example projects for ZML, covering how‑to guides, tutorials, and benchmark examples.
This commit is contained in:
parent
266da6d4be
commit
eded305649
77
docs/howtos/add_weights.md
Normal file
77
docs/howtos/add_weights.md
Normal file
@ -0,0 +1,77 @@
|
||||
|
||||
# Adding Weights Files
|
||||
|
||||
Our [first model](../tutorials/write_first_model.md) did not need any weights files.
|
||||
We just created weights and bias at runtime.
|
||||
|
||||
But real-world models typically need weights files, and maybe some other
|
||||
supporting files.
|
||||
|
||||
We recommend, for easy deployments, you upload those files. In many instances,
|
||||
you will use a site like [🤗 Hugging Face](https://huggingface.co).
|
||||
|
||||
We also recommend to add a `weights.bzl` file to your project root directory, so
|
||||
you don't "pollute" your build file with long URLs and SHAs:
|
||||
|
||||
```python
|
||||
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_file")
|
||||
|
||||
def _weights_impl(mctx):
|
||||
http_file(
|
||||
name = "com_github_zml_cdn_mnist",
|
||||
downloaded_file_path = "mnist.pt",
|
||||
sha256 = "d8a25252e28915e147720c19223721f0f53e3317493727ca754a2dd672450ba9",
|
||||
url = "https://github.com/ggerganov/ggml/raw/18703ad600cc68dbdb04d57434c876989a841d12/examples/mnist/models/mnist/mnist_model.state_dict",
|
||||
)
|
||||
|
||||
http_file(
|
||||
name = "com_github_zml_cdn_mnist_data",
|
||||
downloaded_file_path = "mnist.ylc",
|
||||
sha256 = "0fa7898d509279e482958e8ce81c8e77db3f2f8254e26661ceb7762c4d494ce7",
|
||||
url = "https://github.com/ggerganov/ggml/raw/18703ad600cc68dbdb04d57434c876989a841d12/examples/mnist/models/mnist/t10k-images.idx3-ubyte",
|
||||
)
|
||||
|
||||
return mctx.extension_metadata(
|
||||
reproducible = True,
|
||||
root_module_direct_deps = "all",
|
||||
root_module_direct_dev_deps = [],
|
||||
)
|
||||
|
||||
weights = module_extension(
|
||||
implementation = _weights_impl,
|
||||
)
|
||||
```
|
||||
|
||||
The above `weights.bzl` shows how we load files for MNIST:
|
||||
|
||||
- `mnist.pt` (model weights)
|
||||
- `mnist.ylc` (dataset for picking sample images)
|
||||
|
||||
Then, in your `BUILD.bazel`, you can refer to the files you defined above, in
|
||||
the following way:
|
||||
|
||||
```python
|
||||
zig_cc_binary(
|
||||
name = "mnist",
|
||||
args = [
|
||||
"$(location @com_github_zml_cdn_mnist//file)",
|
||||
"$(location @com_github_zml_cdn_mnist_data//file)",
|
||||
],
|
||||
data = [
|
||||
"@com_github_zml_cdn_mnist//file",
|
||||
"@com_github_zml_cdn_mnist_data//file",
|
||||
],
|
||||
main = "mnist.zig",
|
||||
deps = [
|
||||
"//async",
|
||||
"//zml",
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
See how:
|
||||
|
||||
- we use `data = [ ... ]` to reference the files in `weights.bzl`
|
||||
- we use `args = [ ... ]` to pass the files as command-line arguments to the
|
||||
MNIST executable at runtime, automatically.
|
||||
|
||||
136
docs/howtos/deploy_on_server.md
Normal file
136
docs/howtos/deploy_on_server.md
Normal file
@ -0,0 +1,136 @@
|
||||
|
||||
# Deploying Models on a Server
|
||||
|
||||
To run models on remote GPU/TPU machines, it is inconvenient to have to check
|
||||
out your project’s repository and compile it on every target. Instead, you more
|
||||
likely want to cross-compile right from your development machine, **for every**
|
||||
supported target architecture and accelerator.
|
||||
|
||||
See [Getting Started with ZML](../tutorials/getting_started.md) if you need more
|
||||
information on how to compile a model.
|
||||
|
||||
**Here's a quick recap:**
|
||||
|
||||
You can compile models for accelerator runtimes by appending one or more of the
|
||||
following arguments to the command line when compiling / running a model:
|
||||
|
||||
- NVIDIA CUDA: `--@zml//runtimes:cuda=true`
|
||||
- AMD RoCM: `--@zml//runtimes:rocm=true`
|
||||
- Google TPU: `--@zml//runtimes:tpu=true`
|
||||
- **AVOID CPU:** `--@zml//runtimes:cpu=false`
|
||||
|
||||
So, to run the OpenLLama model from above **on your development machine**
|
||||
housing an NVIDIA GPU, run the following:
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel run -c opt //llama:OpenLLaMA-3B --@zml//runtimes:cuda=true
|
||||
```
|
||||
|
||||
|
||||
## Cross-Compiling and creating a TAR for your server
|
||||
|
||||
Currently, ZML lets you cross-compile to one of the following target
|
||||
architectures:
|
||||
|
||||
- Linux X86_64: `--platforms=@zml//platforms:linux_amd64`
|
||||
- Linux ARM64: `--platforms=@zml//platforms:linux_arm64`
|
||||
- MacOS ARM64: `--platforms=@zml//platforms:macos_arm64`
|
||||
|
||||
As an example, here is how you build above OpenLLama for CUDA on Linux X86_64:
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel build -c opt //llama:OpenLLaMA-3B \
|
||||
--@zml//runtimes:cuda=true \
|
||||
--@zml//runtimes:cpu=false \
|
||||
--platforms=@zml//platforms:linux_amd64
|
||||
```
|
||||
|
||||
### Creating the TAR
|
||||
|
||||
When cross-compiling, it is convenient to produce a compressed TAR file that
|
||||
you can copy to the target host, so you can unpack it there and run the model.
|
||||
|
||||
Let's use MNIST as example.
|
||||
|
||||
If not present already, add an "archive" target to the model's `BUILD.bazel`,
|
||||
like this:
|
||||
|
||||
```python
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
|
||||
# Manifest, required for building the tar archive
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":mnist"],
|
||||
)
|
||||
|
||||
# Create a tar archive from the above manifest
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":mnist"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
```
|
||||
|
||||
... and then build the TAR archive:
|
||||
|
||||
```
|
||||
# cd examples
|
||||
bazel build -c opt //mnist:archive \
|
||||
--@zml//runtimes:cuda=true \
|
||||
--@zml//runtimes:cpu=false \
|
||||
--platforms=@zml//platforms:linux_amd64
|
||||
```
|
||||
|
||||
Note the `//mnist:archive` notation.
|
||||
|
||||
The resulting tar file will be in `bazel-bin/mnist/archive.tar.zst`.
|
||||
|
||||
### Run it on the server
|
||||
|
||||
You can copy the TAR archive onto your Linux X86_64 NVIDIA GPU server, untar
|
||||
and run it:
|
||||
|
||||
```bash
|
||||
# on your machine
|
||||
scp bazel-bin/mnist/archive.tar.zst destination-server:
|
||||
ssh destination-server # to enter the server
|
||||
|
||||
# ... on the server
|
||||
tar xvf archive.tar.zst
|
||||
./mnist \
|
||||
'mnist.runfiles/_main~_repo_rules~com_github_ggerganov_ggml_mnist/file/mnist.pt' \
|
||||
'mnist.runfiles/_main~_repo_rules~com_github_ggerganov_ggml_mnist_data/file/mnist.ylc'
|
||||
```
|
||||
|
||||
The easiest way to figure out the commandline arguments of an example model is
|
||||
to consult the model's `BUILD.bazel` and check out its `args` section. It will
|
||||
reference e.g. weights files that are defined either in the same `BUILD.bazel`
|
||||
file or in a `weights.bzl` file.
|
||||
|
||||
You can also consult the console output when running your model locally:
|
||||
|
||||
```bash
|
||||
bazel run //mnist
|
||||
|
||||
INFO: Analyzed target //mnist:mnist (0 packages loaded, 0 targets configured).
|
||||
INFO: Found 1 target...
|
||||
Target //mnist:mnist up-to-date:
|
||||
bazel-bin/mnist/mnist
|
||||
INFO: Elapsed time: 0.302s, Critical Path: 0.00s
|
||||
INFO: 3 processes: 3 internal.
|
||||
INFO: Build completed successfully, 3 total actions
|
||||
INFO: Running command line: bazel-bin/mnist/mnist ../_main~_repo_rules~com_github_ggerganov_ggml_mnist/file/mnist.pt ../_main~_repo_rules~com_github_ggerganov_ggml_mnist_data/file/mnist.ylc
|
||||
# ...
|
||||
```
|
||||
|
||||
You see the command line right up there. On the server, you just need to replace
|
||||
`../` with the 'runfiles' directory of your TAR.
|
||||
|
||||
376
docs/howtos/dockerize_models.md
Normal file
376
docs/howtos/dockerize_models.md
Normal file
@ -0,0 +1,376 @@
|
||||
|
||||
# Containerize a Model
|
||||
|
||||
A convenient way of [deploying a model](../howtos/deploy_on_server.md) is packaging
|
||||
it up in a Docker container. Thanks to bazel, this is really easy to do. You
|
||||
just have to append a few lines to your model's `BUILD.bazel`. Here is how it's
|
||||
done.
|
||||
|
||||
**Note:** This walkthrough will work with your installed container runtime, no
|
||||
matter if it's **Docker or e.g. Podman.** Also, we'll create images in the
|
||||
[OCI](https://github.com/opencontainers/image-spec) open image format.
|
||||
|
||||
Let's try containerizing our [first model](../tutorials/write_first_model.md), as it
|
||||
doesn't need any additional weights files. We'll see [down below](#adding-weights-and-data)
|
||||
how to add those. We'll also see how to add GPU/TPU support for our container
|
||||
there.
|
||||
|
||||
Bazel creates images from `.TAR` archives.
|
||||
|
||||
The steps required for containerization are:
|
||||
|
||||
1. Let bazel create a MANIFEST for the tar file to come.
|
||||
2. Let bazel create a TAR archive of everything needed for the model to run.
|
||||
- see also: [Deploying Models on a Server](../howtos/deploy_on_server.md), where
|
||||
we prepare a TAR file, and copy it to and run it on a remote GPU server.
|
||||
3. Let bazel create a container image for Linux X86_64.
|
||||
4. Let bazel load the image _(OPTIONAL)_.
|
||||
5. Let bazel push the image straight to the Docker registry.
|
||||
6. Let bazel [add weights and data](#adding-weights-and-data), GPU/TPU support
|
||||
_(OPTIONAL)_.
|
||||
|
||||
**Note:** every TAR archive we create (one in this example) becomes its own
|
||||
layer in the container image.
|
||||
|
||||
## Dockerizing our first model
|
||||
|
||||
We need to add a few "imports" at the beginning of our `BUILD.bazel` so we can
|
||||
use their rules to define our 5 additional targets:
|
||||
|
||||
```python
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
load("@aspect_bazel_lib//lib:transitions.bzl", "platform_transition_filegroup")
|
||||
load("@rules_oci//oci:defs.bzl", "oci_image", "oci_load", "oci_push")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "simple_layer",
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
### 1. The Manifest
|
||||
|
||||
To get started, let's make bazel generate a manifest that will be used when
|
||||
creating the TAR archive.
|
||||
|
||||
```python
|
||||
# Manifest created from the simple_layer binary and friends
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":simple_layer"],
|
||||
)
|
||||
```
|
||||
|
||||
It is as easy as that: we define that we want everything needed for our binary
|
||||
to be included in the manifest.
|
||||
|
||||
|
||||
### 2. The TAR
|
||||
|
||||
Creating the TAR archive is equally easy; it's just a few more lines of bazel:
|
||||
|
||||
```python
|
||||
# Create a tar archive from the above manifest
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":simple_layer"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
```
|
||||
|
||||
Note that we specify high **zstd** compression, which serves two purposes:
|
||||
avoiding large TAR files, and also: creating TAR files that are quick to
|
||||
extract.
|
||||
|
||||
|
||||
### 3. The Image
|
||||
|
||||
Creating the actual image is a two-step process:
|
||||
|
||||
- First, we use a rule that creates an
|
||||
[OCI](https://github.com/opencontainers/image-spec) image (open image
|
||||
format). But we're not done yet.
|
||||
- Second, we force the actual OCI image to be built for `Linux X86_64` always,
|
||||
regardless of the host we're building the image **on**.
|
||||
|
||||
```python
|
||||
# The actual docker image, with entrypoint, created from tar archive
|
||||
oci_image(
|
||||
name = "image_",
|
||||
base = "@distroless_cc_debian12",
|
||||
entrypoint = ["./{}/simple_layer".format(package_name())],
|
||||
tars = [":archive"],
|
||||
)
|
||||
```
|
||||
|
||||
See how we use string interpolation to fill in the folder name for the
|
||||
container's entrypoint?
|
||||
|
||||
|
||||
Next, we use a transition rule to force the container to be built for
|
||||
Linux X86_64:
|
||||
|
||||
```python
|
||||
# We always want to create the image for Linux
|
||||
platform_transition_filegroup(
|
||||
name = "image",
|
||||
srcs = [":image_"],
|
||||
target_platform = "@zml//platforms:linux_amd64",
|
||||
)
|
||||
```
|
||||
|
||||
And that's almost it! You can already build the image:
|
||||
|
||||
```
|
||||
# cd examples
|
||||
bazel build -c opt //simple_layer:image
|
||||
|
||||
INFO: Analyzed target //simple_layer:image (1 packages loaded, 8 targets configured).
|
||||
INFO: Found 1 target...
|
||||
Target //simple_layer:image up-to-date:
|
||||
bazel-out/k8-dbg-ST-f832ad0148ae/bin/simple_layer/image_
|
||||
INFO: Elapsed time: 0.279s, Critical Path: 0.00s
|
||||
INFO: 1 process: 1 internal.
|
||||
INFO: Build completed successfully, 1 total action
|
||||
```
|
||||
|
||||
... and inspect `./bazel-out`. Bazel tells you the exact path to the `image_`.
|
||||
|
||||
|
||||
### 4. The Load
|
||||
|
||||
While inspecting the image is surely interesting, we usually want to load the
|
||||
image so we can run it.
|
||||
|
||||
There is a bazel rule for that: `oci_load`. When we append the following lines
|
||||
to `BUILD.bazel`:
|
||||
|
||||
```python
|
||||
# Load will immediately load the image (eg: docker load)
|
||||
oci_load(
|
||||
name = "load",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/simple_layer:latest",
|
||||
],
|
||||
)
|
||||
```
|
||||
... then we can load the image and run it with the following commands:
|
||||
|
||||
```
|
||||
bazel run -c opt //simple_layer:load
|
||||
docker run --rm distroless/simple_layer:latest
|
||||
```
|
||||
|
||||
|
||||
### 5. The Push
|
||||
|
||||
We just need to add one more target to the build file before we can push the
|
||||
image to a container registry:
|
||||
|
||||
```python
|
||||
# Bazel target for pushing the Linux image to the docker registry
|
||||
oci_push(
|
||||
name = "push",
|
||||
image = ":image",
|
||||
remote_tags = ["latest"],
|
||||
# override with -- --repository foo.bar/org/image
|
||||
repository = "index.docker.io/renerocksai/simple_layer",
|
||||
)
|
||||
```
|
||||
|
||||
This will push the `simple_layer` image with the tag `latest` (you can add more)
|
||||
to the docker registry:
|
||||
|
||||
```
|
||||
bazel run -c opt //simple_layer:push
|
||||
```
|
||||
|
||||
When dealing with maybe a public and a private container registry - or if you
|
||||
just want to try it out **right now**, you can always override the repository on
|
||||
the command line:
|
||||
|
||||
```
|
||||
bazel run -c opt //simple_layer:push -- --repository my.server.com/org/image
|
||||
```
|
||||
|
||||
|
||||
## Adding weights and data
|
||||
|
||||
Dockerizing a model that doesn't need any weights was easy. But what if you want
|
||||
to create a complete care-free package of a model plus all required weights and
|
||||
supporting files?
|
||||
|
||||
We'll use the [MNIST
|
||||
example](https://github.com/zml/zml/tree/master/examples/mnist) to illustrate
|
||||
how to build Docker images that also contain data files.
|
||||
|
||||
You can `bazel run -c opt //mnist:push -- --repository
|
||||
index.docker.io/my_org/zml_mnist` in the `./examples` folder if you want to try
|
||||
it out.
|
||||
|
||||
**Note: Please add one more of the following parameters to specify all the
|
||||
platforms your containerized model should support.**
|
||||
|
||||
- NVIDIA CUDA: `--@zml//runtimes:cuda=true`
|
||||
- AMD RoCM: `--@zml//runtimes:rocm=true`
|
||||
- Google TPU: `--@zml//runtimes:tpu=true`
|
||||
- **AVOID CPU:** `--@zml//runtimes:cpu=false`
|
||||
|
||||
**Example:**
|
||||
|
||||
```
|
||||
bazel run //mnist:push -c opt --@zml//runtimes:cuda=true -- --repository index.docker.io/my_org/zml_mnist
|
||||
```
|
||||
|
||||
|
||||
### Manifest and Archive
|
||||
|
||||
We only add one more target to the `BUILD.bazel` to construct the commandline
|
||||
for the `entrypoint` of the container. All other steps basically remain the
|
||||
same.
|
||||
|
||||
Let's start with creating the manifest and archive:
|
||||
|
||||
```python
|
||||
load("@aspect_bazel_lib//lib:expand_template.bzl", "expand_template")
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
load("@aspect_bazel_lib//lib:transitions.bzl", "platform_transition_filegroup")
|
||||
load("@rules_oci//oci:defs.bzl", "oci_image", "oci_load", "oci_push")
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
# The executable
|
||||
zig_cc_binary(
|
||||
name = "mnist",
|
||||
args = [
|
||||
"$(location @com_github_ggerganov_ggml_mnist//file)",
|
||||
"$(location @com_github_ggerganov_ggml_mnist_data//file)",
|
||||
],
|
||||
data = [
|
||||
"@com_github_ggerganov_ggml_mnist//file",
|
||||
"@com_github_ggerganov_ggml_mnist_data//file",
|
||||
],
|
||||
main = "mnist.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
|
||||
# Manifest created from the executable (incl. its data: weights and dataset)
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":mnist"],
|
||||
)
|
||||
|
||||
# Create a tar archive from the above manifest
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":mnist"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
```
|
||||
|
||||
### Entrypoint
|
||||
|
||||
Our container entrypoint commandline is not just the name of the executable
|
||||
anymore, as we need to pass the weights file and the test dataset to MNIST. A
|
||||
simple string interpolation will not be enough.
|
||||
|
||||
For this reason, we use the `expand_template` rule, like this:
|
||||
|
||||
```python
|
||||
# A convenience template for creating the "command line" for the entrypoint
|
||||
expand_template(
|
||||
name = "entrypoint",
|
||||
data = [
|
||||
":mnist",
|
||||
"@com_github_ggerganov_ggml_mnist//file",
|
||||
"@com_github_ggerganov_ggml_mnist_data//file",
|
||||
],
|
||||
substitutions = {
|
||||
":model": "$(rlocationpath @com_github_ggerganov_ggml_mnist//file)",
|
||||
":data": "$(rlocationpath @com_github_ggerganov_ggml_mnist_data//file)",
|
||||
},
|
||||
template = [
|
||||
"./{}/mnist".format(package_name()),
|
||||
"./{}/mnist.runfiles/:model".format(package_name()),
|
||||
"./{}/mnist.runfiles/:data".format(package_name()),
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
- `data`, which is identical to `data` in the `mnist` target used for running
|
||||
the model, tells bazel which files are needed.
|
||||
- in `substitutions` we define what `:model` and `:data` need to be replaced
|
||||
with
|
||||
- in `template`, we construct the actual entrypoint conmandline
|
||||
|
||||
|
||||
### Image, Push
|
||||
|
||||
From here on, everything is analog to the `simple_layer` example, with one
|
||||
exception: in the `image_` target, we don't fill in the `entrypoint` directly,
|
||||
but use the expanded template, which we conveniently named `entrypoint` above.
|
||||
|
||||
|
||||
```python
|
||||
|
||||
# The actual docker image, with entrypoint, created from tar archive
|
||||
oci_image(
|
||||
name = "image_",
|
||||
base = "@distroless_cc_debian12",
|
||||
# the entrypoint comes from the expand_template rule `entrypoint` above
|
||||
entrypoint = ":entrypoint",
|
||||
tars = [":archive"],
|
||||
)
|
||||
|
||||
# We always want to create the image for Linux
|
||||
platform_transition_filegroup(
|
||||
name = "image",
|
||||
srcs = [":image_"],
|
||||
target_platform = "@zml//platforms:linux_amd64",
|
||||
)
|
||||
|
||||
# Load will immediately load the image (eg: docker load)
|
||||
oci_load(
|
||||
name = "load",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/mnist:latest",
|
||||
],
|
||||
)
|
||||
|
||||
# Bazel target for pushing the Linux image to our docker registry
|
||||
oci_push(
|
||||
name = "push",
|
||||
image = ":image",
|
||||
remote_tags = ["latest"],
|
||||
# override with -- --repository foo.bar/org/image
|
||||
repository = "index.docker.io/steeve/mnist",
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
And that's it! With one simple bazel command, you can push a neatly packaged
|
||||
MNIST model, including weights and dataset, to the docker registry:
|
||||
|
||||
```
|
||||
bazel run //mnist:push --@zml//runtimes:cuda=true -- --repository index.docker.io/my_org/zml_mnist
|
||||
```
|
||||
|
||||
293
docs/howtos/howto_torch2zml.md
Normal file
293
docs/howtos/howto_torch2zml.md
Normal file
@ -0,0 +1,293 @@
|
||||
|
||||
# How to port Pytorch models to ZML ?
|
||||
|
||||
|
||||
## Requirements
|
||||
|
||||
We assume you already have a working ZML project,
|
||||
and you can run it with a Bazel command like `bazel run //my_project:torch2zml`.
|
||||
You can refer to [write your first model](../tutorials/write_first_model.md) to do so.
|
||||
We also assume that you know enough Python to run the reference implementation.
|
||||
|
||||
## Overview
|
||||
|
||||
Porting Neural Network implementations can be tedious. Some small errors can
|
||||
degrade the output of the model, in subtle or not so subtle ways. To track down
|
||||
errors in a model with four thousand layers, we best be organized.
|
||||
|
||||
By the way if you are interested in a specific model, be careful that not all
|
||||
implementations of a model you can find on Github are equivalent. Sometimes
|
||||
people introduce subtle bugs when porting across Python libraries. Ideally use
|
||||
the author's implementation, or at least one you have tested yourself.
|
||||
|
||||
**The recommended process is as follows:**
|
||||
|
||||
1. run the reference implementation on a known input, and sample layer activations
|
||||
2. start a ZML project and load the sampled reference activations
|
||||
3. start porting layers one by one, and test individual layers
|
||||
4. end-to-end test the model
|
||||
|
||||
## Sampling reference activations
|
||||
|
||||
Pytorch exposes "forward hooks" that allow to inspect the input/output of each
|
||||
`torch.nn.Module`. That way it is possible to create a dictionary with each
|
||||
layer input/output, keyed by the name of the layer.
|
||||
|
||||
The main caveat is that if you have a functional implementation that doesn't
|
||||
use `torch.nn.Module`, this technique won't work.
|
||||
|
||||
It is the easiest to start from a "huggingface" snippet, or a python script
|
||||
that calls the model of your choice on an example input. eg:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
import torch
|
||||
import transformers
|
||||
|
||||
model_path = "meta-llama/Meta-Llama-3-8B"
|
||||
|
||||
pipeline = transformers.pipeline(
|
||||
"text-generation",
|
||||
model=model_path,
|
||||
model_kwargs={"torch_dtype": torch.float16},
|
||||
# device="cuda",
|
||||
token=token,
|
||||
)
|
||||
|
||||
prompt = "Q: What is the largest animal?\nA:"
|
||||
output = pipeline(prompt)
|
||||
print(output)
|
||||
```
|
||||
|
||||
Then edit the script to import [zml_utils](https://github.com/zml/zml/blob/master/tools/zml_utils.py).
|
||||
|
||||
`zml_utils.py` is standalone and currently it's not distributed as a python
|
||||
package, so the simplest way to use it, is to copy it next to your python
|
||||
script. Then wrap the model/pipeline in a `zml_utils.ActivationCollector`. The
|
||||
collector wraps the given model, and returns the original results AND the
|
||||
activations in a dict of `torch.Tensor` when it's being called. After that, you
|
||||
can save those activations to a `.pt` file.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import transformers
|
||||
import zml_utils
|
||||
|
||||
model_path = "meta-llama/Meta-Llama-3-8B"
|
||||
|
||||
pipeline = transformers.pipeline(
|
||||
"text-generation",
|
||||
model=model_path,
|
||||
model_kwargs={"torch_dtype": torch.float16},
|
||||
# device="cuda",
|
||||
)
|
||||
model, tokenizer = pipeline.model, pipeline.tokenizer
|
||||
|
||||
prompt = "Q: What is the largest animal?\nA:"
|
||||
# Wrap the pipeline, and extract activations.
|
||||
# Activations files can be huge for big models,
|
||||
# so let's stop collecting after 1000 layers.
|
||||
pipeline = zml_utils.ActivationCollector(pipeline, max_layers=1000, stop_after_first_step=True)
|
||||
output, activations = pipeline(prompt)
|
||||
print(output)
|
||||
|
||||
# Save activations to a file.
|
||||
filename = model_path.split("/")[-1] + ".activations.pt"
|
||||
torch.save(activations, filename)
|
||||
print(f"Saved {len(activations)} activations to {filename}")
|
||||
```
|
||||
|
||||
Run this script: `python activations.py`
|
||||
|
||||
If you're using HuggingFace, make note of the local path where the model is
|
||||
saved, it should be something like `~/.cache/huggingface/hub/...`. (and should
|
||||
appear on the console when running the script). We will need it in the next
|
||||
steps.
|
||||
|
||||
## Loading model and activations in ZML
|
||||
|
||||
Let's create a basic ZML program that loads the activations and the Pytorch
|
||||
model. Put the following in `my_project/torch2zml.zig`.
|
||||
|
||||
```zig
|
||||
const std = @import("std");
|
||||
const log = std.log;
|
||||
|
||||
const asynk = @import("async");
|
||||
const zml = @import("zml");
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
const args = try std.process.argsAlloc(allocator);
|
||||
defer std.process.argsFree(allocator, args);
|
||||
|
||||
const model_path, const activations_path = args[1..3].*;
|
||||
|
||||
const activations = try zml.aio.torch.open(allocator, activations_path);
|
||||
defer activations.deinit();
|
||||
log.info("Found {} activations in {s}", .{ activations.buffers.count(), activations_path });
|
||||
|
||||
const model_weights = try zml.aio.detectFormatAndOpen(allocator, model_path);
|
||||
defer model_weights.deinit();
|
||||
log.info("Found {} model layers in {s}", .{ model_weights.buffers.count(), activations_path });
|
||||
}
|
||||
```
|
||||
|
||||
And add a `zig_cc_binary` target in `my_project/BUILD.bazel`:
|
||||
|
||||
```python
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "torch2zml",
|
||||
main = "torch2zml.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
Now check that the weights can be loaded correctly using the bazel CLI.
|
||||
|
||||
```bash
|
||||
bazel build //my_project:torch2zml
|
||||
./bazel-bin/my_project/torch2zml /path/to/my/model.safetensors.index.json ./my_project/Meta-Llama-3-8B.activations.pt
|
||||
|
||||
info: Found 1108 activations in /Users/guw/Documents/zml/models/torch2zml/Meta-Llama-3-8B.activations.pt
|
||||
debug(zml_io): Loading shard: model-00004-of-00004.safetensors
|
||||
debug(zml_io): Loading shard: model-00001-of-00004.safetensors
|
||||
debug(zml_io): Loading shard: model-00002-of-00004.safetensors
|
||||
debug(zml_io): Loading shard: model-00003-of-00004.safetensors
|
||||
info: Found 291 model layers in /Users/guw/Documents/zml/models/torch2zml/Meta-Llama-3-8B.activations.pt
|
||||
```
|
||||
|
||||
## Loading an individual layer
|
||||
|
||||
In the above Zig code, the `model_weights` struct is a wrapper around a flat
|
||||
dictionary, containing an entry for each tensor in the model (similar to a
|
||||
"state dict"). Manipulating a dictionary is generally not very convenient, so
|
||||
let's convert it to a Zig struct.
|
||||
|
||||
Declare the following layer at the bottom of your file:
|
||||
|
||||
```zig
|
||||
const Mlp = struct {
|
||||
up_proj: zml.nn.Linear,
|
||||
gate_proj: zml.nn.Linear,
|
||||
down_proj: zml.nn.Linear,
|
||||
};
|
||||
```
|
||||
|
||||
The `zml.nn.Linear` is the equivalent of `torch.nn.Linear` and is defined by
|
||||
its `weight` and optional `bias` tensors.
|
||||
|
||||
To create such a struct from our `model_weights` dictionary, we can use the
|
||||
`zml.aio.populateModelWithPrefix` helper:
|
||||
|
||||
```zig
|
||||
pub fn asyncMain() !void {
|
||||
...
|
||||
const mlp_shape = try zml.aio.populateModelWithPrefix(Mlp, allocator, model_weights, "model.layers.0.mlp");
|
||||
log.info("layer.0.mlp: {}", .{mlp_shape});
|
||||
}
|
||||
```
|
||||
|
||||
Build and run, using previous commands.
|
||||
|
||||
Typical errors are of the form _"Layer not found: ..."_. This is typically due
|
||||
to the naming of layers in Zig not matching the naming in the file.
|
||||
Double-check everything and don't hesitate to print more things, e.g. in the
|
||||
Python script. Alternatively, Huggingface's web-interface allows to peek into
|
||||
`.safetensor` files.
|
||||
|
||||
|
||||
## Testing an individual layer
|
||||
|
||||
Finally, we are going to write the actual math code for our `MLP` layer.
|
||||
|
||||
```zig
|
||||
const Mlp = struct {
|
||||
up_proj: zml.nn.Linear,
|
||||
gate_proj: zml.nn.Linear,
|
||||
down_proj: zml.nn.Linear,
|
||||
|
||||
pub fn forward(self: Mlp, x: Tensor) Tensor {
|
||||
const proj = zml.call(self.up_proj, .forward, .{x});
|
||||
var output = zml.call(self.gate_proj, .forward, .{x});
|
||||
output = output.silu().mul(proj);
|
||||
return zml.call(self.down_proj, .forward, .{output});
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
Note that we use `zml.call` instead of directly calling
|
||||
`self.up_proj.forward(x)`. Calling `forward` directly results in the same
|
||||
computation happening at runtime; but going through `zml.call` allows ZML to
|
||||
generate an MLIR representation that is closer to the Zig code and therefore
|
||||
easier to read.
|
||||
|
||||
We can test the MLP layer with the `zml.testing.testLayer` utility:
|
||||
|
||||
```zig
|
||||
pub fn asyncMain() !void {
|
||||
...
|
||||
|
||||
var ctx = try zml.Context.init();
|
||||
defer ctx.deinit();
|
||||
const platform = ctx.autoPlatform();
|
||||
const mlp_weights = try zml.aio.loadModelBuffers(Mlp, mlp_shape, model_weights, allocator, platform);
|
||||
|
||||
zml.testing.testLayer(platform, activations, "model.layers.0.mlp", mlp_shape, mlp_weights, 1e-3);
|
||||
}
|
||||
```
|
||||
|
||||
During this phase, you have three kinds of errors that can appear:
|
||||
|
||||
* Zig compilation errors: we've all have been there, learning a new language
|
||||
can be tough. Normally, the compiler should help you figure out what's wrong.
|
||||
You can also check [ZML concepts](../learn/concepts.md) that explains types used
|
||||
by ZML.
|
||||
* Buffer not found errors: be careful that you need to use
|
||||
the naming scheme of the inference pipeline when loading the activations.
|
||||
Depending on how you write your code, you may have a different naming
|
||||
convention in the model file and in the activation file. This is because in
|
||||
Python, and in particular the `transformers` library, it's not uncommon to
|
||||
wrap the model in a `Pipeline` object before using it. So a given layer may
|
||||
be named `layer.0.mlp` in the model file, but its activations may be saved
|
||||
under `model.layer.0.mlp`.
|
||||
* MLIR compilation errors: typically this is caused by a mathematical
|
||||
error in the `forward` function. To help here, you can log the shapes of the
|
||||
input and intermediary values: `std.log.info("x: {}", .{x})`, and put similar
|
||||
print statements in the Python code. You can also consider splitting a big
|
||||
layer into smaller parts. Since our code only explicitly captures
|
||||
`torch.nn.Module` input/output, you may need to modify the Python script to
|
||||
add some extra tensors to the dictionary with example input/output of a
|
||||
specific function.
|
||||
|
||||
## General tips
|
||||
|
||||
* Porting models can be hard, especially if the original code is messy, has
|
||||
poor comments, behaves differently on different input shapes, or has unused
|
||||
code paths. Start by identifying parts of the Python code which are
|
||||
**unused**. It is common in research code that some code paths were written
|
||||
for one paper, but didn't get used in subsequent papers.
|
||||
|
||||
* ZML offers a few Pytorch specific helpers in `zml.torch`; those operators are
|
||||
offered to help you port models, but in general they may have weird APIs. If
|
||||
you're lucky and the code you are porting has comments indicating "tags", eg
|
||||
"C,W,H" of tensors, you can port this to actual tensor attributes using
|
||||
`x.withTags(.{.c, .w, .h})`, and use those tags (eg `.c`) to refer to axes
|
||||
instead of offsets. E.g. in Pytorch: `x.sum(0) # reduce over channel axis`
|
||||
becomes `x.sum(.c)`. More on this topic in
|
||||
["Working with tensors"](../tutorials/working_with_tensors.md).
|
||||
41
docs/howtos/huggingface_access_token.md
Normal file
41
docs/howtos/huggingface_access_token.md
Normal file
@ -0,0 +1,41 @@
|
||||
|
||||
# Huggingface Token Authentication
|
||||
|
||||
Some models have restrictions and may require some sort of approval or
|
||||
agreement process, which, by consequence, **requires token-authentication with
|
||||
Huggingface**.
|
||||
|
||||
Here is how you can generate a **"read-only public repositories"** access token
|
||||
to log into your account on Huggingface, directly from `bazel`, in order to
|
||||
download models.
|
||||
|
||||
* log in at [https://huggingface.co/settings/tokens](https://huggingface.co/settings/tokens).
|
||||
* click on "Create new token"
|
||||
* give the token a name, eg `zml_public_repos`
|
||||
* under _Repositories_, grant the following permission: "Read access to
|
||||
contents of all public gated repos you can access".
|
||||
* at the bottom, click on "Create token".
|
||||
* copy the token by clicking `Copy`. **You won't be able to see it again.**
|
||||
* the token looks something like `hf_abCdEfGhijKlM`.
|
||||
* store the token on your machine (replace the placeholder with your actual
|
||||
token):
|
||||
|
||||
```
|
||||
echo -n <hf_my_token> > `$HOME/.cache/huggingface/token`
|
||||
```
|
||||
|
||||
The `-n` is important in order to not append an "end of line" character at the
|
||||
end of the file that would corrupt the token.
|
||||
|
||||
Now you're ready to download a gated model like `Meta-Llama-3-8b`!
|
||||
|
||||
**Example:**
|
||||
|
||||
```
|
||||
# requires token in $HOME/.cache/huggingface/token
|
||||
cd examples
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b -- --promt="Once upon a time,"
|
||||
```
|
||||
|
||||
|
||||
33
docs/huggingface-access-token.md
Normal file
33
docs/huggingface-access-token.md
Normal file
@ -0,0 +1,33 @@
|
||||
# Running Gated Huggingface Models with Token Authentication
|
||||
|
||||
Some models have restrictions and may require some sort of approval or agreement
|
||||
process, which, by consequence, **requires token-authentication with Huggingface**.
|
||||
|
||||
Here is how you can generate a **"read-only public repositories"** access token to log into your account on Huggingface, directly from `bazel`, in order to download models.
|
||||
|
||||
* log in at [https://huggingface.co/settings/tokens](https://huggingface.co/settings/tokens).
|
||||
* click on "Create new token"
|
||||
* give the token a name, eg `zml_public_repos`,
|
||||
* under _Repositories_, grant the following permission: "Read access to contents of all public gated repos you can access".
|
||||
* at the bottom click on "Create token".
|
||||
* copy the token by clicking `Copy`. **You won't be able to see it again.**
|
||||
* the token looks something like `hf_abCdEfGhijKlM`.
|
||||
* store the token on your machine (replace the placeholder with your actual token):
|
||||
|
||||
```
|
||||
echo -n <hf_my_token> > `$HOME/.cache/huggingface/token`
|
||||
```
|
||||
|
||||
The `-n` is important in order to not append an "end of line" character at the end of the file that would corrupt the token.
|
||||
|
||||
Now you're ready to download a gated model like `Meta-Llama-3-8b`!
|
||||
|
||||
**Example:**
|
||||
|
||||
```
|
||||
# requires token in $HOME/.cache/huggingface/token
|
||||
cd examples
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b -- --promt="Once upon a time,"
|
||||
```
|
||||
|
||||
161
docs/learn/concepts.md
Normal file
161
docs/learn/concepts.md
Normal file
@ -0,0 +1,161 @@
|
||||
|
||||
# ZML Concepts
|
||||
|
||||
## Model lifecycle
|
||||
|
||||
ZML is an inference stack that helps running Machine Learning (ML) models, and
|
||||
particulary Neural Networks (NN).
|
||||
|
||||
The lifecycle of a model is implemented in the following steps:
|
||||
|
||||
1. Open the model file and read the shapes of the weights, but leave the
|
||||
weights on the disk.
|
||||
|
||||
2. Using the loaded shapes and optional metadata, instantiate a model struct
|
||||
with `Tensor`s, representing the shape and layout of each layer of the NN.
|
||||
|
||||
3. Compile the model struct and it's `forward` function into an accelerator
|
||||
specific executable. The `forward` function describes the mathematical
|
||||
operations corresponding to the model inference.
|
||||
|
||||
4. Load the model weights from disk, onto the accelerator memory.
|
||||
|
||||
5. Bind the model weights to the executable.
|
||||
|
||||
6. Load some user inputs, and copy them to the accelerator.
|
||||
|
||||
7. Call the executable on the user inputs.
|
||||
|
||||
8. Fetch the returned model output from accelerator into host memory, and
|
||||
finally present it to the user.
|
||||
|
||||
9. When all user inputs have been processed, free the executable resources and
|
||||
the associated weights.
|
||||
|
||||
|
||||
**Some details:**
|
||||
|
||||
Note that the compilation and weight loading steps are both bottlenecks to your
|
||||
model startup time, but they can be done in parallel. **ZML provides
|
||||
asynchronous primitives** to make that easy.
|
||||
|
||||
The **compilation can be cached** across runs, and if you're always using the
|
||||
same model architecture with the same shapes, it's possible to by-pass it
|
||||
entirely.
|
||||
|
||||
The accelerator is typically a GPU, but can be another chip, or even the CPU
|
||||
itself, churning vector instructions.
|
||||
|
||||
|
||||
## Tensor Bros.
|
||||
|
||||
In ZML, we leverage Zig's static type system to differentiate between a few
|
||||
concepts, hence we not only have a `Tensor` to work with, like other ML
|
||||
frameworks, but also `Buffer`, `HostBuffer`, and `Shape`.
|
||||
|
||||
Let's explain all that.
|
||||
|
||||
* `Shape`: _describes_ a multi-dimension array.
|
||||
- `Shape.init(.{16}, .f32)` represents a vector of 16 floats of 32 bits
|
||||
precision.
|
||||
- `Shape.init(.{512, 1024}, .f16)` represents a matrix of `512*1024` floats
|
||||
of 16 bits precision, i.e. a `[512][1024]f16` array.
|
||||
|
||||
A `Shape` is only **metadata**, it doesn't point to or own any memory. The
|
||||
`Shape` struct can also represent a regular number, aka a scalar:
|
||||
`Shape.init(.{}, .i32)` represents a 32-bit signed integer.
|
||||
|
||||
* `HostBuffer`: _is_ a multi-dimensional array, whose memory is allocated **on
|
||||
the CPU**.
|
||||
- points to the slice of memory containing the array
|
||||
- typically owns the underlying memory - but has a flag to remember when it
|
||||
doesn't.
|
||||
|
||||
* `Buffer`: _is_ a multi-dimension array, whose memory is allocated **on an
|
||||
accelerator**.
|
||||
- contains a handle that the ZML runtime can use to convert it into a
|
||||
physical address, but there is no guarantee this address is visible from
|
||||
the CPU.
|
||||
- can be created by loading weights from disk directly to the device via
|
||||
`zml.aio.loadBuffers`
|
||||
- can be created by calling `HostBuffer.toDevice(accelerator)`.
|
||||
|
||||
* `Tensor`: is a mathematical object representing an intermediary result of a
|
||||
computation.
|
||||
- is basically a `Shape` with an attached MLIR value representing the
|
||||
mathematical operation that produced this `Tensor`.
|
||||
|
||||
|
||||
## The model struct
|
||||
|
||||
The model struct is the Zig code that describes your Neural Network (NN).
|
||||
Let's look a the following model architecture:
|
||||
|
||||
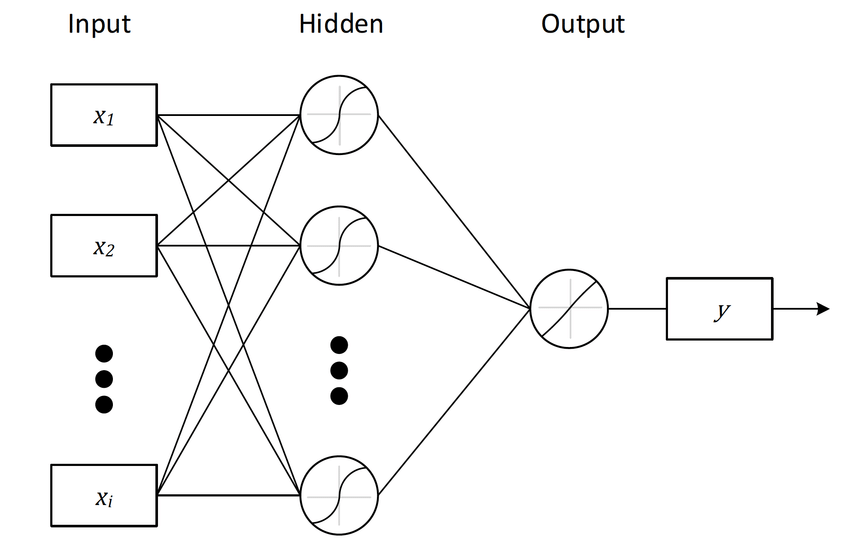
|
||||
|
||||
This is how we can describe it in a Zig struct:
|
||||
|
||||
```zig
|
||||
const Model = struct {
|
||||
input_layer: zml.Tensor,
|
||||
output_layer: zml.Tensor,
|
||||
|
||||
pub fn forward(self: Model, input: zml.Tensor) zml.Tensor {
|
||||
const hidden = self.input_layer.matmul(input);
|
||||
const output = self.output_layer.matmul(hidden);
|
||||
return output;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
NNs are generally seen as a composition of smaller NNs, which are split into
|
||||
layers. ZML makes it easy to mirror this structure in your code.
|
||||
|
||||
```zig
|
||||
const Model = struct {
|
||||
input_layer: MyOtherLayer,
|
||||
output_layer: MyLastLayer,
|
||||
|
||||
pub fn forward(self: Model, input: zml.Tensor) zml.Tensor {
|
||||
const hidden = self.input_layer.forward(input);
|
||||
const output = self.output_layer.forward(hidden);
|
||||
return output;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`zml.nn` module provides a number of well-known layers to more easily bootstrap
|
||||
models.
|
||||
|
||||
Since the `Model` struct contains `Tensor`s, it is only ever useful during the
|
||||
compilation stage, but not during inference. If we want to represent the model
|
||||
with actual `Buffer`s, we can use the `zml.Bufferize(Model)`, which is a mirror
|
||||
struct of `Model` but with a `Buffer` replacing every `Tensor`.
|
||||
|
||||
## Strong type checking
|
||||
|
||||
Let's look at the model life cycle again, but this time annotated with the
|
||||
corresponding types.
|
||||
|
||||
1. Open the model file and read the shapes of the weights -> `zml.HostBuffer`
|
||||
(using memory mapping, no actual copies happen yet)
|
||||
|
||||
2. Instantiate a model struct -> `Model` struct (with `zml.Tensor` inside)
|
||||
|
||||
3. Compile the model struct and its `forward` function into an executable.
|
||||
`foward` is a `Tensor -> Tensor` function, executable is a
|
||||
`zml.Exe(Model.forward)`
|
||||
|
||||
4. Load the model weights from disk, onto accelerator memory ->
|
||||
`zml.Bufferized(Model)` struct (with `zml.Buffer` inside)
|
||||
|
||||
5. Bind the model weights to the executable `zml.ExeWithWeight(Model.forward)`
|
||||
|
||||
6. Load some user inputs (custom struct), encode them into arrays of numbers
|
||||
(`zml.HostBuffer`), and copy them to the accelerator (`zml.Buffer`).
|
||||
|
||||
7. Call the executable on the user inputs. `module.call` accepts `zml.Buffer`
|
||||
arguments and returns `zml.Buffer`
|
||||
|
||||
8. Return the model output (`zml.Buffer`) to the host (`zml.HostBuffer`),
|
||||
decode it (custom struct) and finally return to the user.
|
||||
36
docs/misc/style_guide.md
Normal file
36
docs/misc/style_guide.md
Normal file
@ -0,0 +1,36 @@
|
||||
|
||||
# ZML Style Guide
|
||||
|
||||
We prefer to keep it simple and adhere to the [Zig Style Guide](https://ziglang.org/documentation/0.13.0/#Style-Guide).
|
||||
|
||||
We use ZLS to auto-format code.
|
||||
|
||||
In addition, we try to adhere to the following house-rules:
|
||||
|
||||
### We favor:
|
||||
|
||||
```zig
|
||||
const x: Foo = .{ .bar = 1 }
|
||||
// over: const x = Foo{ .bar = 1}
|
||||
|
||||
pub fn method(self: Foo) void
|
||||
// over: pub fn method(self: Self) void
|
||||
|
||||
const foo = import("foo.zig"); foo.bar()
|
||||
// over: const bar = import("foo.zig").bar;
|
||||
// bar();
|
||||
|
||||
const Foo = import("foo.zig").Foo
|
||||
// over: const Foo = import("Foo.zig")
|
||||
//
|
||||
// Importing types directly instead of using
|
||||
// a namespace should be reserved for very
|
||||
// frequent types.
|
||||
|
||||
|
||||
/// Foo does X and returns Y
|
||||
pub fn foo() usize {
|
||||
// Descriptive doc comments over imperative ones
|
||||
```
|
||||
|
||||
As with the Zig Style Guide: use common sense 😊.
|
||||
145
docs/tutorials/getting_started.md
Normal file
145
docs/tutorials/getting_started.md
Normal file
@ -0,0 +1,145 @@
|
||||
|
||||
# Getting Started with ZML
|
||||
|
||||
In this tutorial, we will install `ZML` and run a few models locally.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
First, let's checkout the ZML codebase. In a terminal, run:
|
||||
|
||||
```
|
||||
git clone https://github.com/zml/zml.git
|
||||
cd zml/
|
||||
```
|
||||
|
||||
We use `bazel` to build ZML and its dependencies. We recommend to download it
|
||||
through `bazelisk`, a version manager for `bazel`.
|
||||
|
||||
|
||||
### Install Bazel:
|
||||
|
||||
**macOs:**
|
||||
|
||||
```
|
||||
brew install bazelisk
|
||||
```
|
||||
|
||||
**Linux:**
|
||||
|
||||
```
|
||||
curl -L -o /usr/local/bin/bazel 'https://github.com/bazelbuild/bazelisk/releases/download/v1.20.0/bazelisk-linux-amd64'
|
||||
chmod +x /usr/local/bin/bazel
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Run a pre-packaged model
|
||||
|
||||
ZML comes with a variety of model examples. See also our reference implementations in the [examples](https://github.com/zml/zml/tree/master/examples/) folder.
|
||||
|
||||
### MNIST
|
||||
|
||||
The [classic](https://en.wikipedia.org/wiki/MNIST_database) handwritten digits
|
||||
recognition task. The model is tasked to recognize a handwritten digit, which
|
||||
has been converted to a 28x28 pixel monochrome image. `Bazel` will download a
|
||||
pre-trained model, and the test dataset. The program will load the model,
|
||||
compile it, and classify a randomly picked example from the test dataset.
|
||||
|
||||
|
||||
On the command line:
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel run -c opt //mnist
|
||||
```
|
||||
|
||||
### Llama
|
||||
|
||||
Llama is a family of "Large Language Models", trained to generate text, based
|
||||
on the beginning of a sentence/book/article. This "beginning" is generally
|
||||
referred to as the "prompt".
|
||||
|
||||
#### TinyLlama, Stories 15M
|
||||
|
||||
To start, you can use a small model trained specifically on children's history
|
||||
books. This model has been trained by [Andrej Karpathy](https://x.com/karpathy);
|
||||
you can read more about it on his
|
||||
[Github](https://github.com/karpathy/llama2.c).
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel run -c opt //llama:TinyLlama-Stories-15M
|
||||
bazel run -c opt //llama:TinyLlama-Stories-15M -- --prompt="Once upon a time, there was a cute little dragon"
|
||||
```
|
||||
|
||||
#### OpenLLama 3B
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel run -c opt //llama:OpenLLaMA-3B
|
||||
bazel run -c opt //llama:OpenLLaMA-3B -- --prompt="Once upon a time,"
|
||||
```
|
||||
|
||||
#### Meta Llama 3 8B
|
||||
|
||||
This model has restrictions, see
|
||||
[here](https://huggingface.co/meta-llama/Meta-Llama-3-8B): it **requires
|
||||
approval from Meta on Huggingface**, which can take a few hours to get granted.
|
||||
|
||||
While waiting for approval, you can already
|
||||
[generate your Huggingface access token](../howtos/huggingface_access_token.md).
|
||||
|
||||
Once you've been granted access, you're ready to download a gated model like
|
||||
`Meta-Llama-3-8b`!
|
||||
|
||||
```
|
||||
# requires token in $HOME/.cache/huggingface/token
|
||||
cd examples
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b
|
||||
bazel run -c opt //llama:Meta-Llama-3-8b -- --promt="Once upon a time,"
|
||||
```
|
||||
|
||||
|
||||
## Run Tests
|
||||
|
||||
```
|
||||
bazel test //zml:test
|
||||
```
|
||||
|
||||
## Running Models on GPU / TPU
|
||||
|
||||
You can compile models for accelerator runtimes by appending one or more of the
|
||||
following arguments to the command line when compiling or running a model:
|
||||
|
||||
- NVIDIA CUDA: `--@zml//runtimes:cuda=true`
|
||||
- AMD RoCM: `--@zml//runtimes:rocm=true`
|
||||
- Google TPU: `--@zml//runtimes:tpu=true`
|
||||
- **AVOID CPU:** `--@zml//runtimes:cpu=false`
|
||||
|
||||
The latter, avoiding compilation for CPU, cuts down compilation time.
|
||||
|
||||
|
||||
So, to run the OpenLLama model from above on your host sporting an NVIDIA GPU,
|
||||
run the following:
|
||||
|
||||
```
|
||||
cd examples
|
||||
bazel run -c opt //llama:OpenLLaMA-3B \
|
||||
--@zml//runtimes:cuda=true \
|
||||
-- --prompt="Once upon a time,"
|
||||
```
|
||||
|
||||
|
||||
## Where to go next:
|
||||
|
||||
In [Deploying Models on a Server](../howtos/deploy_on_server.md), we show how you can
|
||||
cross-compile and package for a specific architecture, then deploy and run your
|
||||
model. Alternatively, you can also [dockerize](../howtos/dockerize_models.md) your
|
||||
model.
|
||||
|
||||
You might also want to check out the
|
||||
[examples](https://github.com/zml/zml/tree/master/examples), read through the
|
||||
[documentation](../README.md), start
|
||||
[writing your first model](../tutorials/write_first_model.md), or read about more
|
||||
high-level [ZML concepts](../learn/concepts.md).
|
||||
|
||||
7
docs/tutorials/working_with_tensors.md
Normal file
7
docs/tutorials/working_with_tensors.md
Normal file
@ -0,0 +1,7 @@
|
||||
|
||||
# Simplifying Dimension Handling with Tagged Tensors
|
||||
|
||||
### Coming Soon...
|
||||
|
||||
See [ZML Concepts](../learn/concepts.md) for an introduction to Tensors and Shapes.
|
||||
|
||||
521
docs/tutorials/write_first_model.md
Normal file
521
docs/tutorials/write_first_model.md
Normal file
@ -0,0 +1,521 @@
|
||||
|
||||
# Writing your first model
|
||||
|
||||
**In this short guide, we will do the following:**
|
||||
|
||||
- clone ZML to work directly within the prepared example folder
|
||||
- add Zig code to implement our model
|
||||
- add some Bazel to integrate our code with ZML
|
||||
- no weights files or anything external is required for this example
|
||||
|
||||
The reason we're doing our excercise in the `examples` folder is because it's
|
||||
especially prepared for new ZML projects. It contains everything needed for ZML
|
||||
development. From `bazel` configs to `vscode` settings, and `neovim` LSP
|
||||
support. The `examples` folder serves as a cookiecutter ZML project example,
|
||||
with just a few example models added already.
|
||||
|
||||
**Note:** _The `examples` folder is self-contained. You **can** make a copy of
|
||||
it to a location outside of the ZML repository. Simply remove all examples you
|
||||
don't need and use it as a template for your own projects._
|
||||
|
||||
So, let's get started, shall we?
|
||||
|
||||
|
||||
|
||||
**If you haven't done so already, please [install bazel](../tutorials/getting_started.md)**.
|
||||
|
||||
|
||||
|
||||
Check out the ZML repository. In the `examples` directory, create a new folder
|
||||
for your project. Let's call it `simple_layer`.
|
||||
|
||||
```
|
||||
git clone https://github.com/zml/zml.git
|
||||
cd zml/examples
|
||||
mkdir -p simple_layer
|
||||
```
|
||||
|
||||
... and add a file `main.zig` to it, along with a bazel build file:
|
||||
|
||||
```
|
||||
touch simple_layer/main.zig
|
||||
touch simple_layer/BUILD.bazel
|
||||
```
|
||||
|
||||
By the way, you can access the complete source code of this walkthrough here:
|
||||
|
||||
- [main.zig](https://github.com/zml/zml/tree/master/examples/simple_layer/main.zig)
|
||||
- [BUILD.bazel](https://github.com/zml/zml/tree/master/examples/simple_layer/BUILD.bazel)
|
||||
|
||||
|
||||
|
||||
## The high-level Overview
|
||||
|
||||
Before firing up our editor, let's quickly talk about a few basic ZML
|
||||
fundamentals.
|
||||
|
||||
In ZML, we describe a _Module_, which represents our AI model, as a Zig
|
||||
`struct`. That struct can contain Tensor fields that are used for computation,
|
||||
e.g. weights and biases. In the _forward_ function of a Module, we describe the
|
||||
computation by calling tensor operations like _mul_, _add_, _dotGeneral_,
|
||||
_conv2D_, etc., or even nested Modules.
|
||||
|
||||
ZML creates an MLIR representation of the computation when we compile the
|
||||
Module. For compilation, only the _Shapes_ of all tensors must be known. No
|
||||
actual tensor data is needed at this step. This is important for large models:
|
||||
we can compile them while the actual weight data is being fetched from disk.
|
||||
|
||||
To accomplish this, ZML uses a _BufferStore_. The _BufferStore_ knows how to
|
||||
only load shapes and when to load actual tensor data. In our example, we will
|
||||
fake the _BufferStore_ a bit: we won't load from disk; we'll use float arrays
|
||||
instead.
|
||||
|
||||
After compilation is done (and the _BufferStore_ has finished loading weights),
|
||||
we can send the weights from the _BufferStore_ to our computation device. That
|
||||
produces an _executable_ module which we can call with different _inputs_.
|
||||
|
||||
In our example, we then copy the result from the computation device to CPU
|
||||
memory and print it.
|
||||
|
||||
**So the steps for us are:**
|
||||
|
||||
- describe the computation as ZML _Module_, using tensor operations
|
||||
- create a _BufferStore_ that provides _Shapes_ and data of weights and bias
|
||||
(ca. 5 lines of code).
|
||||
- compile the _Module_ **asynchronously**
|
||||
- make the compiled _Module_ send the weights (and bias) to the computation
|
||||
device utilizing the _BufferStore_, producing an _executable_ module
|
||||
- prepare input tensor and call the _executable_ module.
|
||||
- get the result back to CPU memory and print it
|
||||
|
||||
If you like to read more about the underlying concepts of the above, please see
|
||||
[ZML Concepts](../learn/concepts.md).
|
||||
|
||||
|
||||
## The code
|
||||
|
||||
Let's start by writing some Zig code, importing ZML and often-used modules:
|
||||
|
||||
```zig
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
|
||||
// shortcut to the async_ function in the asynk module
|
||||
const async_ = asynk.async_;
|
||||
```
|
||||
|
||||
You will use above lines probably in all ZML projects. Also, note that **ZML is
|
||||
async** and comes with its own async runtime, thanks to
|
||||
[zigcoro](https://github.com/rsepassi/zigcoro).
|
||||
|
||||
|
||||
|
||||
### Defining our Model
|
||||
|
||||
We will start with a very simple "Model". One that resembles a "multiply and
|
||||
add" operation.
|
||||
|
||||
```zig
|
||||
/// Model definition
|
||||
const Layer = struct {
|
||||
bias: ?zml.Tensor = null,
|
||||
weight: zml.Tensor,
|
||||
|
||||
pub fn forward(self: Layer, x: zml.Tensor) zml.Tensor {
|
||||
var y = self.weight.mul(x);
|
||||
if (self.bias) |bias| {
|
||||
y = y.add(bias);
|
||||
}
|
||||
return y;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
You see, in ZML AI models are just structs with a forward function!
|
||||
|
||||
There are more things to observe:
|
||||
|
||||
- forward functions typically take Tensors as inputs, and return Tensors.
|
||||
- more advanced use-cases are passing in / returning structs or tuples, like
|
||||
`struct { Tensor, Tensor }` as an example for a tuple of two tensors.
|
||||
You can see such use-cases, for example in the
|
||||
[Llama Model](https://github.com/zml/zml/tree/master/examples/llama)
|
||||
- in the model, tensors may be optional. As is the case with `bias`.
|
||||
|
||||
|
||||
|
||||
### Adding a main() function
|
||||
|
||||
ZML code is async. Hence, We need to provide an async main function. It works
|
||||
like this:
|
||||
|
||||
```zig
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
// ...
|
||||
```
|
||||
|
||||
The above `main()` function only creates an allocator and an async main thread
|
||||
that executes our `asyncMain()` function by calling it with no (`.{}`)
|
||||
arguments.
|
||||
|
||||
So, let's start with the async main function:
|
||||
|
||||
```zig
|
||||
pub fn asyncMain() !void {
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Arena allocator for BufferStore etc.
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const arena = arena_state.allocator();
|
||||
|
||||
// Create ZML context
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
const platform = context.autoPlatform();
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
This is boilerplate code that provides a general-purpose allocator and, for
|
||||
convenience, an arena allocator that we will use later. The advantage of arena
|
||||
allocators is that you don't need to deallocate individual allocations; you
|
||||
simply call `.deinit()` to deinitialize the entire arena instead!
|
||||
|
||||
We also initialize the ZML context `context` and get our CPU `platform`
|
||||
automatically.
|
||||
|
||||
|
||||
### The BufferStore
|
||||
|
||||
Next, we need to set up the concrete weight and bias tensors for our model.
|
||||
Typically, we would load them from disk. But since our example works without
|
||||
stored weights, we are going to create a BufferStore manually, containing
|
||||
_HostBuffers_ (buffers on the CPU) for both the `weight` and the `bias` tensor.
|
||||
|
||||
A BufferStore basically contains a dictionary with string keys that match the
|
||||
name of the struct fields of our `Layer` struct. So, let's create this
|
||||
dictionary:
|
||||
|
||||
```zig
|
||||
// Our weights and bias to use
|
||||
var weights = [3]f16{ 2.0, 2.0, 2.0 };
|
||||
var bias = [3]f16{ 1.0, 2.0, 3.0 };
|
||||
const input_shape = zml.Shape.init(.{3}, .f16);
|
||||
|
||||
// We manually produce a BufferStore. You would not normally do that.
|
||||
// A BufferStore is usually created by loading model data from a file.
|
||||
var buffers: zml.aio.BufferStore.Buffers = .{};
|
||||
try buffers.put(arena, "weight", zml.HostBuffer.fromArray(&weights));
|
||||
try buffers.put(arena, "bias", zml.HostBuffer.fromArray(&bias));
|
||||
|
||||
// the actual BufferStore
|
||||
var bs: zml.aio.BufferStore = .{
|
||||
.arena = arena_state,
|
||||
.buffers = buffers,
|
||||
};
|
||||
```
|
||||
|
||||
Our weights are `{2.0, 2.0, 2.0}`, and our bias is just `{1.0, 2.0, 3.0}`. The
|
||||
shape of the weight and bias tensors is `{3}`, and because of that, the **shape
|
||||
of the input tensor** is also going to be `{3}`!
|
||||
|
||||
Note that `zml.Shape` always takes the data type associated with the tensor. In
|
||||
our example, that is `f16`, expressed as the enum value `.f16`.
|
||||
|
||||
|
||||
|
||||
### Compiling our Module for the accelerator
|
||||
|
||||
We're only going to use the CPU for our simple model, but we need to compile the
|
||||
`forward()` function nonetheless. This compilation is usually done
|
||||
asynchronously. That means, we can continue doing other things while the module
|
||||
is compiling:
|
||||
|
||||
```zig
|
||||
// A clone of our model, consisting of shapes. We only need shapes for compiling.
|
||||
// We use the BufferStore to infer the shapes.
|
||||
const model_shapes = try zml.aio.populateModel(Layer, allocator, bs);
|
||||
|
||||
// Start compiling. This uses the inferred shapes from the BufferStore.
|
||||
// The shape of the input tensor, we have to pass in manually.
|
||||
var compilation = try async_(zml.compileModel, .{ allocator, model_shapes, .forward, .{input_shape}, platform });
|
||||
|
||||
// Produce a bufferized weights struct from the fake BufferStore.
|
||||
// This is like the inferred shapes, but with actual values.
|
||||
// We will need to send those to the computation device later.
|
||||
const model_weights = try zml.aio.loadBuffers(Layer, .{}, bs, arena, platform);
|
||||
defer zml.aio.unloadBuffers(&model_weights); // for good practice
|
||||
|
||||
// Wait for compilation to finish
|
||||
const compiled = try compilation.await_();
|
||||
```
|
||||
|
||||
Compiling is happening in the background via the `async_` function. We call
|
||||
`async_` with the `zml.compileModel` function and its arguments
|
||||
separately. The arguments themselves are basically the shapes of the weights in
|
||||
the BufferStore, the `.forward` function name in order to compile
|
||||
`Layer.forward`, the shape of the input tensor(s), and the platform for which to
|
||||
compile (we used auto platform).
|
||||
|
||||
|
||||
|
||||
### Creating the Executable Model
|
||||
|
||||
Now that we have compiled the module utilizing the shapes, we turn it into an
|
||||
executable.
|
||||
|
||||
```zig
|
||||
// pass the model weights to the compiled module to create an executable module
|
||||
var executable = try compiled.prepare(arena, model_weights);
|
||||
defer executable.deinit();
|
||||
```
|
||||
|
||||
|
||||
### Calling / running the Model
|
||||
|
||||
The executable can now be invoked with an input of our choice.
|
||||
|
||||
To create the `input`, we directly use `zml.Buffer` by calling
|
||||
`zml.Buffer.fromArray()`. It's important to note that `Buffer`s reside in
|
||||
_accelerator_ (or _device_) memory, which is precisely where the input needs to
|
||||
be for the executable to process it on the device.
|
||||
|
||||
For clarity, let's recap the distinction: `HostBuffer`s are located in standard
|
||||
_host_ memory, which is accessible by the CPU. When we initialized the weights,
|
||||
we used `HostBuffers` to set up the `BufferStore`. This is because the
|
||||
`BufferStore` typically loads weights from disk into `HostBuffer`s, and then
|
||||
converts them into `Buffer`s when we call `loadBuffers()`.
|
||||
|
||||
However, for inputs, we bypass the `BufferStore` and create `Buffer`s directly
|
||||
in device memory.
|
||||
|
||||
|
||||
```zig
|
||||
// prepare an input buffer
|
||||
// Here, we use zml.HostBuffer.fromSlice to show how you would create a HostBuffer
|
||||
// with a specific shape from an array.
|
||||
// For situations where e.g. you have an [4]f16 array but need a .{2, 2} input shape.
|
||||
var input = [3]f16{ 5.0, 5.0, 5.0 };
|
||||
var input_buffer = try zml.Buffer.from(platform, zml.HostBuffer.fromSlice(input_shape, &input));
|
||||
defer input_buffer.deinit();
|
||||
|
||||
// call our executable module
|
||||
var result: zml.Buffer = executable.call(.{input_buffer});
|
||||
defer result.deinit();
|
||||
|
||||
// fetch the result buffer to CPU memory
|
||||
const cpu_result = try result.toHostAlloc(arena);
|
||||
std.debug.print(
|
||||
"\n\nThe result of {d} * {d} + {d} = {d}\n",
|
||||
.{ &weights, &input, &bias, cpu_result.items(f16) },
|
||||
);
|
||||
```
|
||||
|
||||
Note that the result of a computation is usually residing in the memory of the
|
||||
computation device, so with `.toHostAlloc()` we bring it back to CPU memory in
|
||||
the form of a `HostBuffer`. After that, we can print it.
|
||||
|
||||
In order to print it, we need to tell the host buffer how to interpret the
|
||||
memory. We do that by calling `.items(f16)`, making it cast the memory to `f16`
|
||||
items.
|
||||
|
||||
And that's it! Now, let's have a look at building and actually running this
|
||||
example!
|
||||
|
||||
|
||||
|
||||
|
||||
## Building it
|
||||
|
||||
As mentioned already, ZML uses Bazel; so to build our model, we just need to
|
||||
create a simple `BUILD.bazel` file, next to the `main.zig` file, like this:
|
||||
|
||||
```python
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "simple_layer",
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
```
|
||||
|
||||
To produce an executable, we import `zig_cc_binary` from the zig rules, and
|
||||
pass it a name and the zig file we just wrote. The dependencies in `deps` are
|
||||
what's needed for a basic ZML executable and correlate with our imports at the
|
||||
top of the Zig file:
|
||||
|
||||
```zig
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
```
|
||||
|
||||
|
||||
## Running it
|
||||
|
||||
With everything in place now, running the model is easy:
|
||||
|
||||
```
|
||||
# run release (-c opt)
|
||||
cd examples
|
||||
bazel run -c opt //simple_layer
|
||||
|
||||
# compile and run debug version
|
||||
bazel run //simple_layer
|
||||
```
|
||||
|
||||
And voila! Here's the output:
|
||||
|
||||
```
|
||||
bazel run -c opt //simple_layer
|
||||
INFO: Analyzed target //simple_layer:simple_layer (0 packages loaded, 0 targets configured).
|
||||
INFO: Found 1 target...
|
||||
Target //simple_layer:simple_layer up-to-date:
|
||||
bazel-bin/simple_layer/simple_layer
|
||||
INFO: Elapsed time: 0.120s, Critical Path: 0.00s
|
||||
INFO: 1 process: 1 internal.
|
||||
INFO: Build completed successfully, 1 total action
|
||||
INFO: Running command line: bazel-bin/simple_layer/simple_layer
|
||||
info(pjrt): Loaded library: libpjrt_cpu.dylib
|
||||
info(zml_module): Compiling main.Layer.forward with { Shape({3}, dtype=.f16) }
|
||||
|
||||
The result of { 2, 2, 2 } * { 5, 5, 5 } + { 1, 2, 3 } = { 11, 12, 13 }
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
You can access the complete source code of this walkthrough here:
|
||||
|
||||
- [main.zig](https://github.com/zml/zml/tree/master/examples/simple_layer/main.zig)
|
||||
- [BUILD.bazel](https://github.com/zml/zml/tree/master/examples/simple_layer/BUILD.bazel)
|
||||
|
||||
|
||||
## The complete example
|
||||
|
||||
```zig
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
/// Model definition
|
||||
const Layer = struct {
|
||||
bias: ?zml.Tensor = null,
|
||||
weight: zml.Tensor,
|
||||
|
||||
pub fn forward(self: Layer, x: zml.Tensor) zml.Tensor {
|
||||
var y = self.weight.mul(x);
|
||||
if (self.bias) |bias| {
|
||||
y = y.add(bias);
|
||||
}
|
||||
return y;
|
||||
}
|
||||
};
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Arena allocator for BufferStore etc.
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const arena = arena_state.allocator();
|
||||
|
||||
// Create ZML context
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
const platform = context.autoPlatform();
|
||||
|
||||
// Our weights and bias to use
|
||||
var weights = [3]f16{ 2.0, 2.0, 2.0 };
|
||||
var bias = [3]f16{ 1.0, 2.0, 3.0 };
|
||||
const input_shape = zml.Shape.init(.{3}, .f16);
|
||||
|
||||
// We manually produce a BufferStore. You would not normally do that.
|
||||
// A BufferStore is usually created by loading model data from a file.
|
||||
var buffers: zml.aio.BufferStore.Buffers = .{};
|
||||
try buffers.put(arena, "weight", zml.HostBuffer.fromArray(&weights));
|
||||
try buffers.put(arena, "bias", zml.HostBuffer.fromArray(&bias));
|
||||
|
||||
// the actual BufferStore
|
||||
const bs: zml.aio.BufferStore = .{
|
||||
.arena = arena_state,
|
||||
.buffers = buffers,
|
||||
};
|
||||
|
||||
// A clone of our model, consisting of shapes. We only need shapes for compiling.
|
||||
// We use the BufferStore to infer the shapes.
|
||||
const model_shapes = try zml.aio.populateModel(Layer, allocator, bs);
|
||||
|
||||
// Start compiling. This uses the inferred shapes from the BufferStore.
|
||||
// The shape of the input tensor, we have to pass in manually.
|
||||
var compilation = try async_(zml.compileModel, .{ allocator, model_shapes, .forward, .{input_shape}, platform });
|
||||
|
||||
// Produce a bufferized weights struct from the fake BufferStore.
|
||||
// This is like the inferred shapes, but with actual values.
|
||||
// We will need to send those to the computation device later.
|
||||
const model_weights = try zml.aio.loadBuffers(Layer, .{}, bs, arena, platform);
|
||||
defer zml.aio.unloadBuffers(&model_weights);
|
||||
|
||||
// Wait for compilation to finish
|
||||
const compiled = try compilation.await_();
|
||||
|
||||
// pass the model weights to the compiled module to create an executable module
|
||||
var executable = try compiled.prepare(arena, model_weights);
|
||||
defer executable.deinit();
|
||||
|
||||
// prepare an input buffer
|
||||
// Here, we use zml.HostBuffer.fromSlice to show how you would create a HostBuffer
|
||||
// with a specific shape from an array.
|
||||
// For situations where e.g. you have an [4]f16 array but need a .{2, 2} input shape.
|
||||
var input = [3]f16{ 5.0, 5.0, 5.0 };
|
||||
var input_buffer = try zml.Buffer.from(platform, zml.HostBuffer.fromSlice(input_shape, &input));
|
||||
defer input_buffer.deinit();
|
||||
|
||||
// call our executable module
|
||||
var result: zml.Buffer = executable.call(.{input_buffer});
|
||||
defer result.deinit();
|
||||
|
||||
// fetch the result to CPU memory
|
||||
const cpu_result = try result.toHostAlloc(arena);
|
||||
std.debug.print(
|
||||
"\n\nThe result of {d} * {d} + {d} = {d}\n",
|
||||
.{ &weights, &input, &bias, cpu_result.items(f16) },
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
## Where to go from here
|
||||
|
||||
- [Add some weights files to your model](../howtos/add_weights.md)
|
||||
- [Run the model on GPU](../tutorials/getting_started.md)
|
||||
- [Deploy the model on a server](../howtos/deploy_on_server.md)
|
||||
- [Dockerize this model](../howtos/dockerize_models.md)
|
||||
- [Learn more about ZML concepts](../learn/concepts.md)
|
||||
- [Find out how to best port PyTorch models](../howtos/howto_torch2zml.md)
|
||||
163
examples/MODULE.bazel
Normal file
163
examples/MODULE.bazel
Normal file
@ -0,0 +1,163 @@
|
||||
module(name = "examples")
|
||||
|
||||
bazel_dep(name = "bazel_skylib", version = "1.7.1")
|
||||
bazel_dep(name = "rules_zig", version = "20240912.0-41bfe84")
|
||||
bazel_dep(name = "platforms", version = "0.0.10")
|
||||
bazel_dep(name = "zml", version = "0.1.0")
|
||||
bazel_dep(name = "aspect_bazel_lib", version = "2.8.1.1")
|
||||
|
||||
bazel_dep(name = "rules_oci", version = "2.0.0")
|
||||
oci = use_extension("@rules_oci//oci:extensions.bzl", "oci")
|
||||
oci.pull(
|
||||
name = "distroless_cc_debian12",
|
||||
digest = "sha256:1850aee2ff72864350058d83d681c757d45c885986d15fcca7309b9e5c69f39a",
|
||||
image = "gcr.io/distroless/cc-debian12",
|
||||
platforms = [
|
||||
"linux/amd64",
|
||||
],
|
||||
)
|
||||
use_repo(oci, "distroless_cc_debian12", "distroless_cc_debian12_linux_amd64")
|
||||
|
||||
# Mnist weights
|
||||
http_file = use_repo_rule("@bazel_tools//tools/build_defs/repo:http.bzl", "http_file")
|
||||
|
||||
http_file(
|
||||
name = "com_github_ggerganov_ggml_mnist",
|
||||
downloaded_file_path = "mnist.pt",
|
||||
sha256 = "d8a25252e28915e147720c19223721f0f53e3317493727ca754a2dd672450ba9",
|
||||
url = "https://github.com/ggerganov/ggml/raw/18703ad600cc68dbdb04d57434c876989a841d12/examples/mnist/models/mnist/mnist_model.state_dict",
|
||||
)
|
||||
|
||||
http_file(
|
||||
name = "com_github_ggerganov_ggml_mnist_data",
|
||||
downloaded_file_path = "mnist.ylc",
|
||||
sha256 = "0fa7898d509279e482958e8ce81c8e77db3f2f8254e26661ceb7762c4d494ce7",
|
||||
url = "https://github.com/ggerganov/ggml/raw/18703ad600cc68dbdb04d57434c876989a841d12/examples/mnist/models/mnist/t10k-images.idx3-ubyte",
|
||||
)
|
||||
|
||||
# Llama weights
|
||||
huggingface = use_extension("@zml//bazel:huggingface.bzl", "huggingface")
|
||||
|
||||
huggingface.model(
|
||||
name = "Karpathy-TinyLlama-Stories",
|
||||
build_file_content = """\
|
||||
load("@bazel_skylib//rules:copy_file.bzl", "copy_file")
|
||||
|
||||
# leverage copy_file to rename tokenizer extension
|
||||
# which allow zml.aio.detectFormatAndLoadTokenizer
|
||||
# to leverage the right tokenizer
|
||||
copy_file(
|
||||
name = "stories15M",
|
||||
src = "stories15M.bin",
|
||||
out = "stories15M.tinyllama",
|
||||
allow_symlink = True,
|
||||
visibility = ["//visibility:public"],
|
||||
)
|
||||
|
||||
copy_file(
|
||||
name = "stories110M",
|
||||
src = "stories110M.bin",
|
||||
out = "stories110M.tinyllama",
|
||||
allow_symlink = True,
|
||||
visibility = ["//visibility:public"],
|
||||
)
|
||||
""",
|
||||
commit = "0bd21da7698eaf29a0d7de3992de8a46ef624add",
|
||||
includes = [
|
||||
"stories15M.bin",
|
||||
"stories110M.bin",
|
||||
],
|
||||
model = "karpathy/tinyllamas",
|
||||
)
|
||||
use_repo(huggingface, "Karpathy-TinyLlama-Stories")
|
||||
|
||||
http_file(
|
||||
name = "Karpathy-TinyLlama-Tokenizer",
|
||||
downloaded_file_path = "stories260K.tinyllama",
|
||||
sha256 = "50a52ef822ee9e83de5ce9d0be0a025a773d019437f58b5ff9dcafb063ece361",
|
||||
url = "https://github.com/karpathy/llama2.c/raw/c02865df300f3bd9e567ce061000dc23bf785a17/tokenizer.bin",
|
||||
)
|
||||
|
||||
huggingface.model(
|
||||
name = "Meta-Llama-3.1-8B-Instruct",
|
||||
build_file_content = """\
|
||||
package(default_visibility = ["//visibility:public"])
|
||||
filegroup(
|
||||
name = "model",
|
||||
srcs = glob(["*.safetensors"]) + ["model.safetensors.index.json"],
|
||||
)
|
||||
|
||||
filegroup(
|
||||
name = "tokenizer",
|
||||
srcs = ["tokenizer.json"],
|
||||
)
|
||||
""",
|
||||
commit = "5206a32e0bd3067aef1ce90f5528ade7d866253f",
|
||||
includes = [
|
||||
"*.safetensors",
|
||||
"model.safetensors.index.json",
|
||||
"tokenizer.json",
|
||||
],
|
||||
model = "meta-llama/Meta-Llama-3.1-8B-Instruct",
|
||||
)
|
||||
use_repo(huggingface, "Meta-Llama-3.1-8B-Instruct")
|
||||
|
||||
huggingface.model(
|
||||
name = "TinyLlama-1.1B-Chat-v1.0",
|
||||
build_file_content = """\
|
||||
package(default_visibility = ["//visibility:public"])
|
||||
|
||||
filegroup(
|
||||
name = "model",
|
||||
srcs = ["model.safetensors"],
|
||||
)
|
||||
|
||||
filegroup(
|
||||
name = "tokenizer",
|
||||
srcs = ["tokenizer.model"],
|
||||
)
|
||||
""",
|
||||
commit = "fe8a4ea1ffedaf415f4da2f062534de366a451e6",
|
||||
includes = [
|
||||
"model.safetensors",
|
||||
"tokenizer.model",
|
||||
],
|
||||
model = "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
|
||||
)
|
||||
use_repo(huggingface, "TinyLlama-1.1B-Chat-v1.0")
|
||||
|
||||
huggingface.model(
|
||||
name = "OpenLM-Research-OpenLLaMA-3B",
|
||||
build_file_content = """\
|
||||
load("@bazel_skylib//rules:copy_file.bzl", "copy_file")
|
||||
|
||||
package(default_visibility = ["//visibility:public"])
|
||||
|
||||
filegroup(
|
||||
name = "model",
|
||||
srcs = ["model.safetensors"],
|
||||
)
|
||||
|
||||
filegroup(
|
||||
name = "tokenizer",
|
||||
srcs = [":tokenizer_pb"],
|
||||
)
|
||||
|
||||
# leverage copy_file to rename tokenizer extension
|
||||
# which allow zml.aio.detectFormatAndLoadTokenizer
|
||||
# to leverage the right tokenizer
|
||||
copy_file(
|
||||
name = "tokenizer_pb",
|
||||
src = "tokenizer.model",
|
||||
out = "tokenizer.pb",
|
||||
allow_symlink = True,
|
||||
)
|
||||
""",
|
||||
commit = "fcc2e809eb8f14dabba84d76a0ddc17b8ea05356",
|
||||
includes = [
|
||||
"model.safetensors",
|
||||
"tokenizer.model",
|
||||
],
|
||||
model = "openlm-research/open_llama_3b",
|
||||
)
|
||||
use_repo(huggingface, "OpenLM-Research-OpenLLaMA-3B")
|
||||
1642
examples/MODULE.bazel.lock
Normal file
1642
examples/MODULE.bazel.lock
Normal file
File diff suppressed because it is too large
Load Diff
36
examples/bazel.sh
Executable file
36
examples/bazel.sh
Executable file
@ -0,0 +1,36 @@
|
||||
#!/bin/bash
|
||||
BAZELISK_VERSION=v1.20.0
|
||||
|
||||
case $OSTYPE in
|
||||
"darwin"*)
|
||||
OS="darwin"
|
||||
CACHE_DIR="${HOME}/Library/Caches/bazelisk"
|
||||
;;
|
||||
"linux"*)
|
||||
OS="linux"
|
||||
if [[ -n "${XDG_CACHE_HOME}" ]]; then
|
||||
CACHE_DIR="${XDG_CACHE_HOME}/bazelisk"
|
||||
else
|
||||
CACHE_DIR="${HOME}/.cache/bazelisk"
|
||||
fi
|
||||
;;
|
||||
esac
|
||||
|
||||
case $(uname -m) in
|
||||
"arm64")
|
||||
ARCH="arm64"
|
||||
;;
|
||||
"x86_64")
|
||||
ARCH="amd64"
|
||||
;;
|
||||
esac
|
||||
|
||||
BAZELISK="${CACHE_DIR}/bazelisk-${BAZELISK_VERSION}"
|
||||
|
||||
if [[ ! -f "${BAZELISK}" ]]; then
|
||||
mkdir -p "${CACHE_DIR}"
|
||||
curl -L -o "${CACHE_DIR}/bazelisk-${BAZELISK_VERSION}" "https://github.com/bazelbuild/bazelisk/releases/download/${BAZELISK_VERSION}/bazelisk-${OS}-${ARCH}"
|
||||
chmod +x "${BAZELISK}"
|
||||
fi
|
||||
|
||||
exec "${BAZELISK}" "$@"
|
||||
11
examples/benchmark/BUILD.bazel
Normal file
11
examples/benchmark/BUILD.bazel
Normal file
@ -0,0 +1,11 @@
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "benchmark",
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
"//third_party/tigerbeetle:flags",
|
||||
],
|
||||
)
|
||||
162
examples/benchmark/main.zig
Normal file
162
examples/benchmark/main.zig
Normal file
@ -0,0 +1,162 @@
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
const flags = @import("tigerbeetle/flags");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
/// Model definition
|
||||
const Benchmark = struct {
|
||||
pub fn forward(self: Benchmark, a: zml.Tensor, b: zml.Tensor) zml.Tensor {
|
||||
_ = self;
|
||||
return a.dot(b, .{.k});
|
||||
}
|
||||
};
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
const CliArgs = struct {
|
||||
pub const help =
|
||||
\\ benchmark --size=4096 --dtype=f16
|
||||
;
|
||||
size: usize = 4096,
|
||||
dtype: zml.DataType = .f16,
|
||||
};
|
||||
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Arena allocator for BufferStore etc.
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const arena = arena_state.allocator();
|
||||
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
// Auto-select platform
|
||||
const platform = context.autoPlatform();
|
||||
{
|
||||
// List available targets
|
||||
std.debug.print("Available Platforms:\n", .{});
|
||||
const selected_prefix = "✅";
|
||||
const not_selected_prefix = "• ";
|
||||
const selected_postfix = "(AUTO-SELECTED)\n";
|
||||
const not_selected_postfix = "\n";
|
||||
for (zml.platform.available_targets) |target| {
|
||||
std.debug.print(" {s} {s} {s}", .{
|
||||
if (target == platform.target) selected_prefix else not_selected_prefix,
|
||||
@tagName(target),
|
||||
if (target == platform.target) selected_postfix else not_selected_postfix,
|
||||
});
|
||||
|
||||
// now the platform's devices
|
||||
if (context.platforms.get(target)) |pfm| {
|
||||
for (pfm.getDevices(), 0..) |device, index| {
|
||||
const deviceKind = device.getDescription(platform.pjrt_api).getKind(platform.pjrt_api);
|
||||
std.debug.print(" ◦ #{d}: {s}\n", .{
|
||||
index,
|
||||
deviceKind,
|
||||
});
|
||||
// we only list 1 CPU device
|
||||
if (target == .cpu) break;
|
||||
}
|
||||
}
|
||||
}
|
||||
std.debug.print("\n", .{});
|
||||
}
|
||||
|
||||
var args = std.process.args();
|
||||
const cli_args = flags.parse(&args, CliArgs);
|
||||
|
||||
const input_shape = zml.Shape.init(.{ cli_args.size, cli_args.size }, cli_args.dtype);
|
||||
|
||||
var timer = try std.time.Timer.start();
|
||||
|
||||
std.debug.print("\nCompiling model to MLIR....\n", .{});
|
||||
std.debug.print("-" ** 160 ++ "\n", .{});
|
||||
// Start compiling.
|
||||
// The shape of the input tensor, we have to pass in manually.
|
||||
timer.reset();
|
||||
var compilation = try async_(zml.module.compileModel, .{ allocator, Benchmark{}, .forward, .{ input_shape.withTags(.{ .m, .k }), input_shape.withTags(.{ .k, .n }) }, platform });
|
||||
|
||||
// Wait for compilation to finish
|
||||
const compiled = try compilation.await_();
|
||||
const compilation_elapsed = timer.lap() / std.time.ns_per_ms;
|
||||
std.debug.print("-" ** 160 ++ "\n\n", .{});
|
||||
std.debug.print("✅ Compiled Benchmark model in {d} milliseconds! \n", .{compilation_elapsed});
|
||||
|
||||
// pass the model weights to the compiled module to create an executable module
|
||||
var executable = try compiled.prepare(arena, .{});
|
||||
defer executable.deinit();
|
||||
|
||||
var rng = std.Random.DefaultPrng.init(0);
|
||||
const random = rng.random();
|
||||
|
||||
var a_buffer = try createRandomBuffer(allocator, platform, input_shape, random);
|
||||
defer a_buffer.deinit();
|
||||
var b_buffer = try createRandomBuffer(allocator, platform, input_shape, random);
|
||||
defer b_buffer.deinit();
|
||||
|
||||
std.debug.print("\nRunning benchmark....\n", .{});
|
||||
|
||||
// Ignore first run
|
||||
{
|
||||
var result: zml.Buffer = executable.call(.{ a_buffer, b_buffer });
|
||||
defer result.deinit();
|
||||
}
|
||||
|
||||
// call our executable module
|
||||
timer.reset();
|
||||
var result: zml.Buffer = executable.call(.{ a_buffer, b_buffer });
|
||||
defer result.deinit();
|
||||
const elapsed_ns = timer.lap();
|
||||
const elapsed_ms = @as(f64, @floatFromInt(elapsed_ns)) / std.time.ns_per_ms;
|
||||
const elapsed_s = @as(f64, @floatFromInt(elapsed_ns)) / std.time.ns_per_s;
|
||||
|
||||
std.debug.print("\n✅ Benchmark done!\n\n", .{});
|
||||
|
||||
const floating_op_count = 2 * cli_args.size * cli_args.size * cli_args.size;
|
||||
const flops = @as(f64, @floatFromInt(floating_op_count)) / elapsed_s;
|
||||
std.debug.print("Dot product size: {d}x{d} - Datatype: {s} - Elapsed: {d:.3}ms - {d:.3} GFLOP/s\n\n", .{ cli_args.size, cli_args.size, @tagName(cli_args.dtype), elapsed_ms, flops / 1_000_000_000 });
|
||||
}
|
||||
|
||||
fn createRandomBuffer(allocator: std.mem.Allocator, platform: zml.Platform, shape: zml.Shape, random: std.Random) !zml.Buffer {
|
||||
const data = try allocator.alloc(u8, shape.byteSize());
|
||||
defer allocator.free(data);
|
||||
|
||||
switch (shape.dtype()) {
|
||||
inline else => |v| {
|
||||
const ZigType = v.toZigType();
|
||||
switch (comptime v.class()) {
|
||||
.bool => unreachable,
|
||||
.integer => {
|
||||
for (std.mem.bytesAsSlice(ZigType, data)) |*e| e.* = random.int(ZigType);
|
||||
},
|
||||
.float => {
|
||||
const value = random.float(f64);
|
||||
for (std.mem.bytesAsSlice(ZigType, data)) |*e| e.* = if (ZigType == f64)
|
||||
value
|
||||
else if (ZigType == f32)
|
||||
@floatCast(value)
|
||||
else if (ZigType == f16)
|
||||
@floatCast(value)
|
||||
else
|
||||
@bitCast(random.int(std.meta.Int(.unsigned, @bitSizeOf(ZigType))));
|
||||
},
|
||||
.complex => unreachable,
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
var host_buffer = zml.HostBuffer.fromBytes(shape, data);
|
||||
errdefer host_buffer.deinit(allocator);
|
||||
return zml.Buffer.from(platform, host_buffer);
|
||||
}
|
||||
0
examples/build.zig
Normal file
0
examples/build.zig
Normal file
158
examples/llama/BUILD.bazel
Normal file
158
examples/llama/BUILD.bazel
Normal file
@ -0,0 +1,158 @@
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
load("@aspect_bazel_lib//lib:transitions.bzl", "platform_transition_filegroup")
|
||||
load("@bazel_skylib//rules:native_binary.bzl", "native_binary")
|
||||
load("@rules_oci//oci:defs.bzl", "oci_image", "oci_load", "oci_push")
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "llama",
|
||||
srcs = [
|
||||
"llama.zig",
|
||||
],
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"//third_party/tigerbeetle:flags",
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
|
||||
native_binary(
|
||||
name = "Llama-3.1-8B-Instruct",
|
||||
src = ":llama",
|
||||
args = [
|
||||
"--model=$(location @Meta-Llama-3.1-8B-Instruct//:model.safetensors.index.json)",
|
||||
"--tokenizer=$(location @Meta-Llama-3.1-8B-Instruct//:tokenizer)",
|
||||
"--num-heads=32",
|
||||
"--num-kv-heads=8",
|
||||
"--rope-freq-base=500000",
|
||||
],
|
||||
data = [
|
||||
"@Meta-Llama-3.1-8B-Instruct//:model",
|
||||
"@Meta-Llama-3.1-8B-Instruct//:model.safetensors.index.json",
|
||||
"@Meta-Llama-3.1-8B-Instruct//:tokenizer",
|
||||
],
|
||||
)
|
||||
|
||||
native_binary(
|
||||
name = "OpenLLaMA-3B",
|
||||
src = ":llama",
|
||||
args = [
|
||||
"--model=$(location @OpenLM-Research-OpenLLaMA-3B//:model)",
|
||||
"--tokenizer=$(location @OpenLM-Research-OpenLLaMA-3B//:tokenizer)",
|
||||
"--num-heads=32",
|
||||
"--num-kv-heads=32",
|
||||
"--rope-freq-base=10000",
|
||||
],
|
||||
data = [
|
||||
"@OpenLM-Research-OpenLLaMA-3B//:model",
|
||||
"@OpenLM-Research-OpenLLaMA-3B//:tokenizer",
|
||||
],
|
||||
)
|
||||
|
||||
native_binary(
|
||||
name = "TinyLlama-1.1B-Chat",
|
||||
src = ":llama",
|
||||
args = [
|
||||
"--model=$(location @TinyLlama-1.1B-Chat-v1.0//:model.safetensors)",
|
||||
"--tokenizer=$(location @TinyLlama-1.1B-Chat-v1.0//:tokenizer)",
|
||||
"--num-heads=32",
|
||||
"--num-kv-heads=4",
|
||||
"--rope-freq-base=10000",
|
||||
],
|
||||
data = [
|
||||
"@TinyLlama-1.1B-Chat-v1.0//:model.safetensors",
|
||||
"@TinyLlama-1.1B-Chat-v1.0//:tokenizer",
|
||||
],
|
||||
)
|
||||
|
||||
native_binary(
|
||||
name = "TinyLlama-Stories-110M",
|
||||
src = ":llama",
|
||||
args = [
|
||||
"--model=$(location @Karpathy-TinyLlama-Stories//:stories110M)",
|
||||
"--tokenizer=$(location @Karpathy-TinyLlama-Tokenizer//file)",
|
||||
],
|
||||
data = [
|
||||
"@Karpathy-TinyLlama-Stories//:stories110M",
|
||||
"@Karpathy-TinyLlama-Tokenizer//file",
|
||||
],
|
||||
)
|
||||
|
||||
native_binary(
|
||||
name = "TinyLlama-Stories-15M",
|
||||
src = ":llama",
|
||||
args = [
|
||||
"--model=$(location @Karpathy-TinyLlama-Stories//:stories15M)",
|
||||
"--tokenizer=$(location @Karpathy-TinyLlama-Tokenizer//file)",
|
||||
],
|
||||
data = [
|
||||
"@Karpathy-TinyLlama-Stories//:stories15M",
|
||||
"@Karpathy-TinyLlama-Tokenizer//file",
|
||||
],
|
||||
)
|
||||
|
||||
zig_cc_binary(
|
||||
name = "test-implementation",
|
||||
srcs = ["llama.zig"],
|
||||
args = [
|
||||
"--model=$(location @Meta-Llama-3.1-8B-Instruct//:model.safetensors.index.json)",
|
||||
"--num-heads=32",
|
||||
"--num-kv-heads=8",
|
||||
"--rope-freq-base=500000",
|
||||
],
|
||||
data = [
|
||||
"@Meta-Llama-3.1-8B-Instruct//:model",
|
||||
"@Meta-Llama-3.1-8B-Instruct//:model.safetensors.index.json",
|
||||
],
|
||||
main = "test.zig",
|
||||
deps = [
|
||||
"//third_party/tigerbeetle:flags",
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":llama"],
|
||||
)
|
||||
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":llama"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
|
||||
oci_image(
|
||||
name = "image_",
|
||||
base = "@distroless_cc_debian12",
|
||||
entrypoint = ["./{}/llama".format(package_name())],
|
||||
tars = [":archive"],
|
||||
)
|
||||
|
||||
platform_transition_filegroup(
|
||||
name = "image",
|
||||
srcs = [":image_"],
|
||||
target_platform = "@zml//platforms:linux_amd64",
|
||||
)
|
||||
|
||||
oci_load(
|
||||
name = "load",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/llama:latest",
|
||||
],
|
||||
)
|
||||
|
||||
oci_push(
|
||||
name = "push",
|
||||
image = ":image",
|
||||
remote_tags = ["latest"],
|
||||
repository = "index.docker.io/steeve/llama",
|
||||
)
|
||||
384
examples/llama/llama.zig
Normal file
384
examples/llama/llama.zig
Normal file
@ -0,0 +1,384 @@
|
||||
const std = @import("std");
|
||||
const testing = std.testing;
|
||||
|
||||
const zml = @import("zml");
|
||||
const meta = zml.meta;
|
||||
const flags = @import("tigerbeetle/flags");
|
||||
|
||||
const log = std.log.scoped(.llama);
|
||||
const gguf = zml.io.gguf;
|
||||
const Buffer = zml.Buffer;
|
||||
const Tensor = zml.Tensor;
|
||||
const ShapeOf = zml.ShapeOf;
|
||||
const expectClose = zml.testing.expectClose;
|
||||
|
||||
pub const LlamaOptions = struct {
|
||||
gen_opts: zml.nn.SamplingStrategy,
|
||||
max_seq_len: u32,
|
||||
num_heads: i64,
|
||||
num_kv_heads: i64,
|
||||
rms_norm_eps: f32,
|
||||
rope_opts: zml.nn.RopeOpts,
|
||||
};
|
||||
|
||||
/// Llama architecture, using huggingface transformers naming.
|
||||
/// Dimensions of activations: {.b, .s, .d}
|
||||
pub const LlamaLM = struct {
|
||||
lm_head: zml.nn.Linear,
|
||||
model: Llama,
|
||||
|
||||
// Options controlling generation
|
||||
gen_opts: zml.nn.SamplingStrategy = .{},
|
||||
|
||||
pub fn init(self: *LlamaLM, options: LlamaOptions) void {
|
||||
self.gen_opts = options.gen_opts;
|
||||
self.model.max_seq_len = options.max_seq_len;
|
||||
self.model.num_heads = options.num_heads;
|
||||
self.model.num_kv_heads = options.num_kv_heads;
|
||||
self.model.rope_opts = options.rope_opts;
|
||||
for (self.model.layers) |*layer| {
|
||||
layer.self_attn.num_heads = options.num_heads;
|
||||
layer.self_attn.num_kv_heads = options.num_kv_heads;
|
||||
layer.self_attn.rope_opts = options.rope_opts;
|
||||
layer.input_layernorm.eps = options.rms_norm_eps;
|
||||
layer.post_attention_layernorm.eps = options.rms_norm_eps;
|
||||
}
|
||||
}
|
||||
|
||||
/// Predicts the token at `token_index` position.
|
||||
/// Returns:
|
||||
/// - updated `tokens`,
|
||||
/// - `token_idx` + 1,
|
||||
/// - updated KV cache
|
||||
/// - a Rng state to allow for probabilistic generation
|
||||
pub fn forward(
|
||||
self: LlamaLM,
|
||||
tokens_: Tensor,
|
||||
token_index: Tensor,
|
||||
kv_cache: ?KvCache,
|
||||
rng: Tensor.Rng,
|
||||
) struct { Tensor, Tensor, KvCache, Tensor.Rng } {
|
||||
meta.assert(tokens_.dtype() == .i32 and tokens_.rank() >= 1 and token_index.dtype() == .i32 and token_index.rank() == 0, "Can't run Llama ! Expected >=1d tokens and 0d token_index, got: {} and {}", .{ tokens_, token_index });
|
||||
|
||||
var tokens = tokens_.withPartialTags(.{.s});
|
||||
const out, const updated_kv_cache = zml.call(self.model, .forward, .{ tokens, if (kv_cache == null) null else token_index, kv_cache });
|
||||
tokens, const new_rng = updateTokens(self.lm_head, tokens, token_index, out, rng, self.gen_opts);
|
||||
return .{ tokens, increment(0, token_index), updated_kv_cache, new_rng };
|
||||
}
|
||||
|
||||
pub fn updateTokens(
|
||||
lm_head: zml.nn.Linear,
|
||||
tokens_: Tensor,
|
||||
token_index: Tensor,
|
||||
out_: Tensor,
|
||||
rng: Tensor.Rng,
|
||||
opts: zml.nn.SamplingStrategy,
|
||||
) struct { Tensor, Tensor.Rng } {
|
||||
const tokens = tokens_.withPartialTags(.{.s});
|
||||
const out = out_.withPartialTags(.{ .s, .d });
|
||||
|
||||
const next_token_pred = out.dynamicSlice(.{ .s = .{ .start = token_index, .len = 1 } });
|
||||
var logits = zml.call(lm_head, .forward, .{next_token_pred});
|
||||
if (logits.shape().hasTag(.voc) == null)
|
||||
logits = logits.rename(.{ .d = .voc });
|
||||
|
||||
const next_token, const new_rng = zml.nn.sampleTokens(logits, opts, rng);
|
||||
const next_token_index = token_index.addConstant(1);
|
||||
const new_tokens = tokens.dynamicUpdateSlice(.{ .s = next_token_index }, next_token);
|
||||
|
||||
return .{ new_tokens.reuseBuffer(tokens_), new_rng };
|
||||
}
|
||||
|
||||
pub fn increment(_: u8, token_index: Tensor) Tensor {
|
||||
return token_index.addConstant(1).reuseBuffer(token_index);
|
||||
}
|
||||
|
||||
/// Run the generation entirely within pjrt.
|
||||
pub fn generate(self: LlamaLM, tokens: Tensor, token_index: Tensor, rng: Tensor.Rng) Tensor {
|
||||
// Generate the first token using the prompt and generate the KV-cache initial values.
|
||||
const prefill = zml.call(self, .forward, .{ tokens, token_index, null, rng });
|
||||
|
||||
const Gen = struct {
|
||||
/// Same as LlamaLM.forward but without optional in the signature
|
||||
pub fn forward(lm: LlamaLM, t_ids: Tensor, t_idx: Tensor, kv_cache_: KvCache, inner_rng: Tensor.Rng) struct { Tensor, Tensor, KvCache, Tensor.Rng } {
|
||||
var kv_cache = kv_cache_;
|
||||
kv_cache.k = kv_cache.k.withPartialTags(.{ .layer, .h, .k, .hd });
|
||||
kv_cache.v = kv_cache.v.withPartialTags(.{ .layer, .h, .k, .hd });
|
||||
return zml.call(lm, .forward, .{ t_ids._ctx, t_ids, t_idx, kv_cache, inner_rng });
|
||||
}
|
||||
// / Stops when we generated `max_seq_len` tokens.
|
||||
pub fn shouldContinue(lm: LlamaLM, t_ids: Tensor, t_idx: Tensor, kv_cache: KvCache, inner_rng: Tensor.Rng) Tensor {
|
||||
_ = kv_cache;
|
||||
_ = inner_rng;
|
||||
std.debug.assert(t_ids.dim(1) == lm.model.max_seq_len);
|
||||
return t_idx.cmp(.LT, Tensor.scalar(t_ids._ctx, lm.model.max_seq_len, t_idx.dtype()));
|
||||
}
|
||||
};
|
||||
// Generate remaining tokens using the KV-cache, return tokens.
|
||||
return zml.ops.while_(Gen.shouldContinue, Gen.forward, self, prefill)[0];
|
||||
}
|
||||
};
|
||||
|
||||
pub const Llama = struct {
|
||||
embed_tokens: zml.nn.TokenEmbedding,
|
||||
norm: RmsNorm,
|
||||
layers: []TransformerLayer,
|
||||
|
||||
max_seq_len: u32 = 0,
|
||||
num_heads: i64 = 32,
|
||||
num_kv_heads: i64 = 32,
|
||||
rope_opts: zml.nn.RopeOpts = .{
|
||||
.impl = .interleaved,
|
||||
.freq_base = 10_000,
|
||||
},
|
||||
|
||||
const Shape = struct {
|
||||
s: u32,
|
||||
layer: u16,
|
||||
hd: u16,
|
||||
nh: u16,
|
||||
nkvh: u16,
|
||||
dtype: zml.DataType,
|
||||
};
|
||||
|
||||
pub fn shape(self: Llama) Shape {
|
||||
const key_dim = self.layers[0].self_attn.k_proj.weight.dim(0);
|
||||
const num_kv_heads = if (self.num_kv_heads > 0) self.num_kv_heads else self.num_heads;
|
||||
|
||||
return .{
|
||||
.s = self.max_seq_len,
|
||||
.layer = @intCast(self.layers.len),
|
||||
.hd = @intCast(@divExact(key_dim, num_kv_heads)),
|
||||
.nh = @intCast(self.num_heads),
|
||||
.nkvh = @intCast(num_kv_heads),
|
||||
.dtype = self.embed_tokens.weight.dtype(),
|
||||
};
|
||||
}
|
||||
|
||||
/// Forward one token, using KV cache for previous tokens.
|
||||
/// Returns result and updated KV cache.
|
||||
pub fn forward(self: Llama, tokens: Tensor, token_index: ?Tensor, kv_cache: ?KvCache) struct { Tensor, KvCache } {
|
||||
const embeds = embed(self.embed_tokens, tokens, token_index);
|
||||
|
||||
var hidden = embeds;
|
||||
const kv_cache0 = kv_cache orelse self.initKvCache(embeds.shape());
|
||||
|
||||
var updated_kv_cache = kv_cache0;
|
||||
for (self.layers, 0..) |layer, i| {
|
||||
hidden, updated_kv_cache = zml.call(layer, .forward, .{ hidden, token_index, updated_kv_cache.atLayer(i) });
|
||||
hidden = hidden.withPartialTags(.{ .s, .d });
|
||||
}
|
||||
// TODO: tags seem to be lost by `callFunc`.
|
||||
const output = zml.call(self.norm, .forward, .{hidden.withPartialTags(.{ .s, .d })});
|
||||
|
||||
return .{ output, updated_kv_cache.reuseBuffer(kv_cache0) };
|
||||
}
|
||||
|
||||
pub fn embed(embed_tokens_: zml.nn.TokenEmbedding, tokens_: Tensor, token_index: ?Tensor) Tensor {
|
||||
const tokens = if (token_index) |idx|
|
||||
tokens_.dynamicSlice1d(-1, 1, idx)
|
||||
else
|
||||
tokens_;
|
||||
return zml.call(embed_tokens_, .forward, .{tokens}).withPartialTags(.{ .s, .d });
|
||||
}
|
||||
|
||||
fn initKvCache(self: Llama, embed_shape: zml.Shape) KvCache {
|
||||
const dims = self.shape();
|
||||
var kv_shape = embed_shape.insert(0, .{ .layer = dims.layer }).rename(.{ .s = .k }).splitAxes(.{ .d = .{ .h = dims.nkvh, .hd = dims.hd } });
|
||||
const perm = kv_shape.contiguousPerm(.{ .h, .k, .hd });
|
||||
kv_shape = kv_shape.transpose(perm.constSlice());
|
||||
return KvCache.init(kv_shape);
|
||||
}
|
||||
};
|
||||
|
||||
pub const TransformerLayer = struct {
|
||||
input_layernorm: RmsNorm,
|
||||
self_attn: SelfAttn,
|
||||
post_attention_layernorm: RmsNorm,
|
||||
mlp: Mlp,
|
||||
|
||||
pub fn forward(
|
||||
self: TransformerLayer,
|
||||
x0: Tensor,
|
||||
token_index: ?Tensor,
|
||||
kv_cache: ?KvCache,
|
||||
) struct { Tensor, KvCache } {
|
||||
// Self Attention
|
||||
//log.debug("TransformerLayer({}) -> {}", .{ x0, self.input_layernorm.forward(x0) });
|
||||
meta.assert(x0.rank() >= 2 and x0.shape().hasTags(.{ .s, .d }), "TransformerLayer expected input shape: {{..., .s, .d}}, received: {}", .{x0});
|
||||
|
||||
const x0_normalized = zml.call(self.input_layernorm, .forward, .{x0});
|
||||
const delta0, const updated_kv_cache = zml.call(self.self_attn, .forward, .{ x0_normalized, token_index, kv_cache });
|
||||
const x1 = x0.add(delta0);
|
||||
|
||||
// Fully Connected
|
||||
const x1_normalized = zml.call(self.post_attention_layernorm, .forward, .{x1});
|
||||
const x2 = zml.call(self.mlp, .forward, .{x1_normalized}).add(x1);
|
||||
|
||||
return .{ x2.reuseBuffer(x0), updated_kv_cache };
|
||||
}
|
||||
};
|
||||
|
||||
const RmsNorm = struct {
|
||||
weight: Tensor,
|
||||
eps: f32 = 1e-5,
|
||||
|
||||
/// L2 normalization of input tensor along `.d` axis.
|
||||
pub fn forward(self: RmsNorm, input: Tensor) Tensor {
|
||||
const x = if (input.shape().isFullyTagged()) input else input.withPartialTags(.{.d});
|
||||
// upcast to improve precision
|
||||
const xf32 = x.convert(.f32);
|
||||
const mean = xf32.mul(xf32).mean(.d);
|
||||
const rsqrt = Tensor.rsqrt(mean.addConstant(self.eps)).convert(x.dtype());
|
||||
const normalized = x.mul(rsqrt.broad(x.shape()));
|
||||
|
||||
return normalized.mul(self.weight.convert(x.dtype()).withTags(.{.d}).broad(x.shape()));
|
||||
}
|
||||
};
|
||||
|
||||
const Mlp = struct {
|
||||
up_proj: zml.nn.Linear, // (dim -> hidden_dim)
|
||||
gate_proj: zml.nn.Linear, // (dim -> hidden_dim)
|
||||
down_proj: zml.nn.Linear, // (hidden_dim -> dim)
|
||||
|
||||
pub fn forward(self: Mlp, x: Tensor) Tensor {
|
||||
const proj = zml.call(self.up_proj, .forward, .{x});
|
||||
var output = zml.call(self.gate_proj, .forward, .{x});
|
||||
output = output.silu().mul(proj);
|
||||
return zml.call(self.down_proj, .forward, .{output});
|
||||
}
|
||||
};
|
||||
|
||||
pub const SelfAttn = struct {
|
||||
q_proj: zml.nn.Linear,
|
||||
k_proj: zml.nn.Linear,
|
||||
v_proj: zml.nn.Linear,
|
||||
|
||||
o_proj: zml.nn.Linear,
|
||||
num_heads: i64 = undefined,
|
||||
num_kv_heads: i64 = 0,
|
||||
rope_opts: zml.nn.RopeOpts = undefined,
|
||||
|
||||
/// Self Attention.
|
||||
/// - If token_index is set, x is assumed to be the representation of one new token,
|
||||
/// and kv_cache will be read for the previous tokens.
|
||||
/// - If token_index is not set, x is assumed to be the representation of all tokens
|
||||
/// since the beginning of the sequence, and kv_cache won't be read.
|
||||
/// In both case, kv_cache will be updated with the computed key and value.
|
||||
/// x: {.b, .s, .d } -> .{.b, .s, .d}
|
||||
pub fn forward(
|
||||
self: SelfAttn,
|
||||
x: Tensor,
|
||||
token_index: ?Tensor,
|
||||
kv_cache_: ?KvCache,
|
||||
) struct { Tensor, KvCache } {
|
||||
// log.debug("x.shape: {}", .{x.shape()});
|
||||
const num_kv_heads = if (self.num_kv_heads > 0) self.num_kv_heads else self.num_heads;
|
||||
var q = zml.call(self.q_proj, .forward, .{x}).splitAxis(-1, .{ .h = self.num_heads, .hd = .auto });
|
||||
var k = zml.call(self.k_proj, .forward, .{x}).splitAxis(-1, .{ .h = num_kv_heads, .hd = .auto });
|
||||
var v = zml.call(self.v_proj, .forward, .{x}).splitAxis(-1, .{ .h = num_kv_heads, .hd = .auto });
|
||||
// Generate the attention mask.
|
||||
const kv_cache = kv_cache_ orelse initKvCache(k.shape());
|
||||
const seq_len = kv_cache.k.dim(.k);
|
||||
var attn_mask = zml.nn.causalAttnMask(.{ .q = seq_len, .k = seq_len }, x.dtype(), null);
|
||||
var cos, var sin = zml.nn.ropeCosSin(.{ .s = seq_len, .hd = k.dim(.hd) }, x.dtype(), self.rope_opts);
|
||||
if (token_index) |idx| {
|
||||
// Note: in Pytorch it would be very inefficient to generate the full ropeCosSin and attn_mask matrices, then slice into it,
|
||||
// but XLA is able to optimize this correctly.
|
||||
attn_mask = attn_mask.dynamicSlice(.{ .q = .{ .start = idx, .len = 1 } });
|
||||
cos = cos.dynamicSlice(.{ .s = .{ .start = idx, .len = 1 } });
|
||||
sin = sin.dynamicSlice(.{ .s = .{ .start = idx, .len = 1 } });
|
||||
}
|
||||
|
||||
// In self-attention, .s axis is used both for keys and queries.
|
||||
q = zml.nn.rope(q, .{ cos, sin }, self.rope_opts);
|
||||
k = zml.nn.rope(k, .{ cos, sin }, self.rope_opts);
|
||||
q = q.rename(.{ .s = .q });
|
||||
k = k.rename(.{ .s = .k });
|
||||
v = v.rename(.{ .s = .k });
|
||||
|
||||
const new_kv_cache = kv_cache.update(k, v, token_index orelse Tensor.scalar(0, .i32));
|
||||
if (token_index) |_| {
|
||||
std.debug.assert(q.dim(.q) == 1);
|
||||
k = new_kv_cache.keys();
|
||||
v = new_kv_cache.values();
|
||||
}
|
||||
|
||||
const attn_output = zml.nn.sdpa(q, k, v, .{ .attn_mask = attn_mask, .allow_cudnn = false });
|
||||
const attn = attn_output.merge(.{ .d = .{ .h, .hd } }).rename(.{ .q = .s });
|
||||
return .{ zml.call(self.o_proj, .forward, .{attn}), new_kv_cache };
|
||||
}
|
||||
|
||||
fn initKvCache(key_shape: zml.Shape) KvCache {
|
||||
// When we call initKvCache, we haven't renamed .s to .k yet.
|
||||
var kv_shape = key_shape.insert(0, .{ .layer = 1 }).rename(.{ .s = .k });
|
||||
const perm = kv_shape.contiguousPerm(.{ .h, .k, .hd });
|
||||
kv_shape = kv_shape.transpose(perm.constSlice());
|
||||
var res = KvCache.init(kv_shape);
|
||||
res.layer_index = Tensor.scalar(0, .i32);
|
||||
return res;
|
||||
}
|
||||
};
|
||||
|
||||
pub const KvCache = struct {
|
||||
k: Tensor,
|
||||
v: Tensor,
|
||||
layer_index: Tensor,
|
||||
|
||||
pub fn init(kv_shape: zml.Shape) KvCache {
|
||||
// The KV-cache is initialized with ones to detect reads of uninitialized memory.
|
||||
return .{
|
||||
.k = Tensor.constant(kv_shape, kv_shape.dtype().one()),
|
||||
.v = Tensor.constant(kv_shape, kv_shape.dtype().one()),
|
||||
.layer_index = Tensor.scalar(-1, .i32),
|
||||
};
|
||||
}
|
||||
|
||||
pub fn initShape(kv_shape: zml.Shape) ShapeOf(KvCache) {
|
||||
return .{
|
||||
.k = kv_shape,
|
||||
.v = kv_shape,
|
||||
.layer_index = zml.Shape.init(.{}, .i32),
|
||||
};
|
||||
}
|
||||
|
||||
pub fn keys(self: KvCache) Tensor {
|
||||
return self.k.dynamicSlice(.{ .layer = .{ .start = self.layer_index, .len = 1 } }).squeeze(.layer);
|
||||
}
|
||||
|
||||
pub fn values(self: KvCache) Tensor {
|
||||
return self.v.dynamicSlice(.{ .layer = .{ .start = self.layer_index, .len = 1 } }).squeeze(.layer);
|
||||
}
|
||||
|
||||
pub fn update(self: KvCache, new_k: Tensor, new_v: Tensor, token_index: Tensor) KvCache {
|
||||
return .{
|
||||
.k = self.k.dynamicUpdateSlice(
|
||||
.{ .layer = self.layer_index, .k = token_index },
|
||||
// transpose to match kv-cache layout
|
||||
new_k.contiguous(.{ .h, .k, .hd }),
|
||||
).reuseBuffer(self.k),
|
||||
.v = self.v.dynamicUpdateSlice(
|
||||
.{ .layer = self.layer_index, .k = token_index },
|
||||
// transpose to match kv-cache layout
|
||||
new_v.contiguous(.{ .h, .k, .hd }),
|
||||
).reuseBuffer(self.v),
|
||||
.layer_index = self.layer_index,
|
||||
};
|
||||
}
|
||||
|
||||
pub fn atLayer(self: KvCache, layer_index: usize) KvCache {
|
||||
return .{
|
||||
.k = self.k,
|
||||
.v = self.v,
|
||||
.layer_index = Tensor.scalar(layer_index, .i32),
|
||||
};
|
||||
}
|
||||
|
||||
pub fn reuseBuffer(self: KvCache, other: KvCache) KvCache {
|
||||
return .{
|
||||
.k = self.k.reuseBuffer(other.k),
|
||||
.v = self.v.reuseBuffer(other.v),
|
||||
.layer_index = self.layer_index.reuseBuffer(other.layer_index),
|
||||
};
|
||||
}
|
||||
};
|
||||
265
examples/llama/main.zig
Normal file
265
examples/llama/main.zig
Normal file
@ -0,0 +1,265 @@
|
||||
const std = @import("std");
|
||||
|
||||
const zml = @import("zml");
|
||||
const meta = zml.meta;
|
||||
const asynk = @import("async");
|
||||
const flags = @import("tigerbeetle/flags");
|
||||
const llama_mod = @import("llama.zig");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
const LlamaLM = llama_mod.LlamaLM;
|
||||
const Llama = llama_mod.Llama;
|
||||
const KvCache = llama_mod.KvCache;
|
||||
const TransformerLayer = llama_mod.TransformerLayer;
|
||||
const SelfAttn = llama_mod.SelfAttn;
|
||||
const Buffer = zml.Buffer;
|
||||
const Tensor = zml.Tensor;
|
||||
const ShapeOf = zml.ShapeOf;
|
||||
|
||||
const log = std.log.scoped(.llama);
|
||||
|
||||
// set this to false to disable the verbose logging
|
||||
const show_mlir = true;
|
||||
|
||||
pub const std_options = .{
|
||||
.log_level = .err,
|
||||
.log_scope_levels = &[_]std.log.ScopeLevel{
|
||||
.{ .scope = .pjrt, .level = if (show_mlir) .debug else .err },
|
||||
.{ .scope = .zml_module, .level = if (show_mlir) .debug else .err },
|
||||
.{ .scope = .zml, .level = if (show_mlir) .debug else .err },
|
||||
.{ .scope = .llama, .level = if (show_mlir) .debug else .info },
|
||||
},
|
||||
};
|
||||
|
||||
pub fn generateText(
|
||||
llama: LlamaLM,
|
||||
mod_prefill: zml.module.ExeWithWeights(LlamaLM.forward),
|
||||
mod: zml.module.ExeWithWeights(LlamaLM.forward),
|
||||
tokenizer: zml.tokenizer.Tokenizer,
|
||||
allocator: std.mem.Allocator,
|
||||
seed: u128,
|
||||
prompt: []const u8,
|
||||
) ![]const u8 {
|
||||
const prompt_tok = tokenizer.encode(allocator, prompt, .{}) catch unreachable;
|
||||
log.debug("Tokenized Prompt {d}", .{prompt_tok});
|
||||
const dims = llama.model.shape();
|
||||
const max_seq_len = dims.s;
|
||||
const token_buffer = try allocator.alloc(i32, @intCast(max_seq_len));
|
||||
@memset(token_buffer, 0);
|
||||
for (0..prompt_tok.len) |i| {
|
||||
token_buffer[i] = @intCast(prompt_tok[i]);
|
||||
}
|
||||
|
||||
const tracer_buffer = try allocator.alloc(u8, @intCast(max_seq_len));
|
||||
defer allocator.free(token_buffer);
|
||||
defer allocator.free(tracer_buffer);
|
||||
defer allocator.free(prompt_tok);
|
||||
var output = std.ArrayList(u8).init(allocator);
|
||||
defer output.deinit();
|
||||
|
||||
var tokens = try zml.Buffer.fromSlice(mod.platform(), .{max_seq_len}, token_buffer);
|
||||
var token_index = try zml.Buffer.fromSlice(mod.platform(), .{}, &[_]i32{@intCast(prompt_tok.len - 1)});
|
||||
|
||||
var rng = try zml.Tensor.Rng.init(mod.platform(), seed);
|
||||
tokens, token_index, var kv_cache, rng = mod_prefill.call(.{ tokens, token_index, null, rng });
|
||||
defer kv_cache.k.deinit();
|
||||
defer kv_cache.v.deinit();
|
||||
defer kv_cache.layer_index.deinit();
|
||||
|
||||
const tracer = zml.tools.Tracer.init("ai.zml.models.llama");
|
||||
var decode_progress = prompt_tok.len;
|
||||
const output_tokens_len = max_seq_len - prompt_tok.len - 1;
|
||||
|
||||
const start = std.time.microTimestamp();
|
||||
const output_freq: u8 = 1;
|
||||
for (0..output_tokens_len) |i| {
|
||||
//_ = i;
|
||||
const frame_id = tracer.frameStart(try std.fmt.bufPrintZ(tracer_buffer, "Generate token {}/{}", .{ i + 1, output_tokens_len }));
|
||||
tokens, token_index, kv_cache, rng = mod.call(.{ tokens, token_index, kv_cache, rng });
|
||||
if ((i + 1) % output_freq == 0) {
|
||||
const n = output.items.len;
|
||||
_ = try tokens.toHost(std.mem.sliceAsBytes(token_buffer));
|
||||
try tokenizer.decodeWithOpts(&output, @ptrCast(token_buffer[decode_progress..][0..output_freq]), .{});
|
||||
decode_progress += output_freq;
|
||||
std.debug.print("{s}", .{output.items[n..]});
|
||||
tracer.frameEnd(frame_id, try std.fmt.bufPrintZ(tracer_buffer, "Decoded token {}/{} : {s}", .{ i + 1, output_tokens_len, output.items[n..] }));
|
||||
} else {
|
||||
tracer.frameEnd(frame_id, try std.fmt.bufPrintZ(tracer_buffer, "Generated token {}/{}", .{ i + 1, output_tokens_len }));
|
||||
}
|
||||
}
|
||||
std.debug.print("\n", .{});
|
||||
|
||||
const n = output.items.len;
|
||||
try tokenizer.decodeWithOpts(&output, @ptrCast(token_buffer[decode_progress..]), .{});
|
||||
std.debug.print("{s}\n", .{output.items[n..]});
|
||||
const end = std.time.microTimestamp();
|
||||
|
||||
const duration = zml.meta.divFloat(f64, end - start, std.time.us_per_s);
|
||||
const speed = @as(f64, @floatFromInt(max_seq_len)) / duration;
|
||||
log.info("✅ Generated {d} tokens in {:.3}s: {d:.3}tok/s", .{ max_seq_len, duration, speed });
|
||||
|
||||
_ = try tokens.toHost(std.mem.sliceAsBytes(token_buffer));
|
||||
const end_index = std.mem.indexOfScalar(i32, token_buffer, 128001) orelse max_seq_len;
|
||||
output.clearRetainingCapacity();
|
||||
|
||||
try tokenizer.decodeWithOpts(&output, @ptrCast(token_buffer[0..end_index]), .{});
|
||||
return output.toOwnedSlice();
|
||||
}
|
||||
|
||||
pub fn main() !void {
|
||||
try asynk.AsyncThread.main(std.heap.c_allocator, asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
const CliArgs = struct {
|
||||
pub const help =
|
||||
\\ llama --model=llama3.7B.safetensors --tokenizer=vocab.json --num_layers=2
|
||||
;
|
||||
model: []const u8,
|
||||
tokenizer: ?[]const u8 = null,
|
||||
layer_start: u8 = 0,
|
||||
num_layers: ?u8 = null,
|
||||
seq_len: u32 = 256,
|
||||
topk: u32 = 2,
|
||||
temperature: u32 = 1,
|
||||
num_heads: ?i64 = null,
|
||||
num_kv_heads: ?i64 = null,
|
||||
rope_freq_base: ?i64 = null,
|
||||
prompt: ?[]const u8 = null,
|
||||
test_activations: ?[]const u8 = null,
|
||||
seed: ?u128 = null,
|
||||
};
|
||||
|
||||
log.info(" LLama was compiled with {}", .{@import("builtin").mode});
|
||||
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{ .thread_safe = true }){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
const tmp = try std.fs.openDirAbsolute("/tmp", .{});
|
||||
try tmp.makePath("zml/llama/cache");
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
const compilation_options = zml.CompilationOptions{
|
||||
.cache_location = "/tmp/zml/llama/cache",
|
||||
.xla_dump_to = "/tmp/zml/llama",
|
||||
};
|
||||
|
||||
const platform = context.autoPlatform().withCompilationOptions(compilation_options);
|
||||
{
|
||||
// List available targets
|
||||
std.debug.print("\nSupported Platforms:\n", .{});
|
||||
const selected_prefix = "✅";
|
||||
const not_selected_prefix = "• ";
|
||||
const selected_postfix = "(AUTO-SELECTED)\n";
|
||||
const not_selected_postfix = "\n";
|
||||
for (zml.platform.available_targets) |target| {
|
||||
std.debug.print(" {s} {s} {s}", .{
|
||||
if (target == platform.target) selected_prefix else not_selected_prefix,
|
||||
@tagName(target),
|
||||
if (target == platform.target) selected_postfix else not_selected_postfix,
|
||||
});
|
||||
|
||||
// now the platform's devices
|
||||
if (context.platforms.get(target)) |pfm| {
|
||||
for (pfm.getDevices(), 0..) |device, index| {
|
||||
const deviceKind = device.getDescription(platform.pjrt_api).getKind(platform.pjrt_api);
|
||||
std.debug.print(" ◦ #{d}: {s}\n", .{
|
||||
index,
|
||||
deviceKind,
|
||||
});
|
||||
// we only list 1 CPU device
|
||||
if (target == .cpu) break;
|
||||
}
|
||||
}
|
||||
}
|
||||
std.debug.print("\n", .{});
|
||||
}
|
||||
|
||||
var args = std.process.args();
|
||||
const cli_args = flags.parse(&args, CliArgs);
|
||||
const model_file = cli_args.model;
|
||||
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const model_arena = arena_state.allocator();
|
||||
|
||||
log.info("Model file: {s}", .{model_file});
|
||||
|
||||
var ts = try zml.aio.detectFormatAndOpen(allocator, model_file);
|
||||
defer ts.deinit();
|
||||
|
||||
var llama = try zml.aio.populateModel(LlamaLM, model_arena, ts);
|
||||
const num_heads: i64 = cli_args.num_heads orelse ts.metadata("num_heads", .int64) orelse @panic("--num_heads is required for this model");
|
||||
const num_kv_heads: i64 = cli_args.num_kv_heads orelse ts.metadata("num_kv_heads", .int64) orelse num_heads;
|
||||
|
||||
const rope_impl = if (ts.metadata("rope_impl", .string)) |val|
|
||||
std.meta.stringToEnum(zml.nn.RopeOpts.Implementation, val).?
|
||||
else
|
||||
.sequential;
|
||||
|
||||
const llama_options: llama_mod.LlamaOptions = .{
|
||||
.max_seq_len = cli_args.seq_len,
|
||||
.num_kv_heads = num_kv_heads,
|
||||
.num_heads = num_heads,
|
||||
.gen_opts = .{
|
||||
.topk = cli_args.topk,
|
||||
.temperature = @floatFromInt(cli_args.temperature),
|
||||
},
|
||||
.rms_norm_eps = @floatCast(ts.metadata("rms_norm_eps", .float64) orelse 1e-5),
|
||||
.rope_opts = .{
|
||||
.impl = rope_impl,
|
||||
.freq_base = @floatCast(ts.metadata("rope_freq_base", .float64) orelse @as(f32, @floatFromInt(cli_args.rope_freq_base orelse 10_000))),
|
||||
},
|
||||
};
|
||||
log.info("✅ Parsed llama config: {}", .{llama_options});
|
||||
llama.init(llama_options);
|
||||
|
||||
if (cli_args.tokenizer == null and !std.mem.endsWith(u8, cli_args.model, ".gguf")) {
|
||||
log.err("Model doesn't have an embbedded tokenizer, please provide a path to a tokenizer.", .{});
|
||||
@panic("No tokenizer provided");
|
||||
}
|
||||
const tokenizer_path = cli_args.tokenizer orelse cli_args.model;
|
||||
log.info(" Loading tokenizer from {s}", .{tokenizer_path});
|
||||
var tokenizer = try zml.aio.detectFormatAndLoadTokenizer(allocator, tokenizer_path);
|
||||
log.info("✅ Loaded tokenizer from {s}", .{tokenizer_path});
|
||||
defer tokenizer.deinit();
|
||||
|
||||
const dims = llama.model.shape();
|
||||
const dtype = llama.lm_head.weight.dtype();
|
||||
|
||||
// Note: we compile the model without a batching dimension.
|
||||
// To do so, we would just need to add `.b = batch_size` to `token_shape` and `kv_shape`.
|
||||
const tokens_shape = zml.Shape.init(.{ .s = dims.s }, .i32);
|
||||
const token_idx_shape = zml.Shape.init(.{}, .i32);
|
||||
const kv_shape = zml.Shape.init(.{ .layer = llama.model.layers.len, .h = dims.nkvh, .k = dims.s, .hd = dims.hd }, dtype);
|
||||
// needs to be optional
|
||||
const kv_cache_shape: ?ShapeOf(KvCache) = KvCache.initShape(kv_shape);
|
||||
const rng_shape = Tensor.Rng.shape();
|
||||
|
||||
const compile_start = std.time.milliTimestamp();
|
||||
var fut_mod_prefill = try async_(zml.compile, .{ allocator, LlamaLM, .{llama_options}, .forward, .{ tokens_shape, token_idx_shape, null, rng_shape }, ts, platform });
|
||||
var fut_mod = try async_(zml.compile, .{ allocator, LlamaLM, .{llama_options}, .forward, .{ tokens_shape, token_idx_shape, kv_cache_shape, rng_shape }, ts, platform });
|
||||
|
||||
log.info("Starting loading weights", .{});
|
||||
var llama_weights = try zml.aio.loadBuffers(LlamaLM, .{llama_options}, ts, model_arena, platform);
|
||||
defer zml.aio.unloadBuffers(&llama_weights);
|
||||
log.info("✅ Done loading weights", .{});
|
||||
log.info("✅ Llama model loaded from {s}", .{cli_args.model});
|
||||
|
||||
var llama_module_prefill = try (try fut_mod_prefill.await_()).prepare(allocator, llama_weights);
|
||||
defer llama_module_prefill.deinit();
|
||||
var llama_module = try (try fut_mod.await_()).prepare(allocator, llama_weights);
|
||||
defer llama_module.deinit();
|
||||
const compile_end = std.time.milliTimestamp();
|
||||
log.info("✅ Compiled model in {d} milliseconds! \n", .{compile_end - compile_start});
|
||||
|
||||
const prompt = cli_args.prompt orelse "Once upon a time, there was a little girl named Lily.";
|
||||
log.info("✅ Prompt: {s}\n", .{prompt});
|
||||
|
||||
const seed = cli_args.seed orelse @as(u128, @bitCast(std.time.nanoTimestamp()));
|
||||
const story = try generateText(llama, llama_module_prefill, llama_module, tokenizer, allocator, seed, prompt);
|
||||
defer allocator.free(story);
|
||||
}
|
||||
126
examples/llama/test.zig
Normal file
126
examples/llama/test.zig
Normal file
@ -0,0 +1,126 @@
|
||||
const std = @import("std");
|
||||
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
const flags = @import("tigerbeetle/flags");
|
||||
|
||||
const llama_mod = @import("./llama.zig");
|
||||
const LlamaLM = llama_mod.LlamaLM;
|
||||
|
||||
const Tensor = zml.Tensor;
|
||||
|
||||
pub fn main() !void {
|
||||
try asynk.AsyncThread.main(std.heap.c_allocator, asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
const CliArgs = struct {
|
||||
pub const help =
|
||||
\\ test-implementation --model=llama3.8B.safetensors --reference=activation.safetensors
|
||||
;
|
||||
model: []const u8,
|
||||
reference: []const u8,
|
||||
num_heads: ?i64 = null,
|
||||
num_kv_heads: ?i64 = null,
|
||||
rope_freq_base: ?i64 = null,
|
||||
};
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{ .thread_safe = true }){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Create ZML context
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
// Select platform
|
||||
const platform = context.autoPlatform();
|
||||
|
||||
// Parse program args
|
||||
var args = std.process.args();
|
||||
const cli_args = flags.parse(&args, CliArgs);
|
||||
const model_file = cli_args.model;
|
||||
|
||||
// Memory arena dedicated to model shapes and weights
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const model_arena = arena_state.allocator();
|
||||
|
||||
std.log.info("Model file: {s}", .{model_file});
|
||||
|
||||
// Read model shapes.
|
||||
var buffer_store = try zml.aio.detectFormatAndOpen(allocator, model_file);
|
||||
defer buffer_store.deinit();
|
||||
|
||||
// Create the model and configure it.
|
||||
var llama = try zml.aio.populateModel(LlamaLM, model_arena, buffer_store);
|
||||
const num_heads: i64 = cli_args.num_heads orelse buffer_store.metadata("num_heads", .int64) orelse @panic("--num_heads is required for this model");
|
||||
const num_kv_heads: i64 = cli_args.num_kv_heads orelse buffer_store.metadata("num_kv_heads", .int64) orelse num_heads;
|
||||
|
||||
const rope_impl = if (buffer_store.metadata("rope_impl", .string)) |val|
|
||||
std.meta.stringToEnum(zml.nn.RopeOpts.Implementation, val).?
|
||||
else
|
||||
.sequential;
|
||||
|
||||
const llama_options: llama_mod.LlamaOptions = .{
|
||||
.max_seq_len = 256,
|
||||
.num_kv_heads = num_kv_heads,
|
||||
.num_heads = num_heads,
|
||||
.gen_opts = .{},
|
||||
.rms_norm_eps = @floatCast(buffer_store.metadata("rms_norm_eps", .float64) orelse 1e-5),
|
||||
.rope_opts = .{
|
||||
.impl = rope_impl,
|
||||
.freq_base = @floatCast(buffer_store.metadata("rope_freq_base", .float64) orelse @as(f32, @floatFromInt(cli_args.rope_freq_base orelse 10_000))),
|
||||
},
|
||||
};
|
||||
std.log.info("Parsed llama config: {}", .{llama_options});
|
||||
llama.init(llama_options);
|
||||
|
||||
// Load the weights.
|
||||
var llama_weights = try zml.aio.loadBuffers(LlamaLM, .{llama_options}, buffer_store, model_arena, platform);
|
||||
defer zml.aio.unloadBuffers(&llama_weights);
|
||||
|
||||
// Load the activations.
|
||||
var activation_buffer_store = try zml.aio.torch.open(allocator, cli_args.reference);
|
||||
defer activation_buffer_store.deinit();
|
||||
|
||||
// Test implementation
|
||||
try testImplementation(platform, llama, llama_weights, activation_buffer_store);
|
||||
}
|
||||
|
||||
fn testImplementation(
|
||||
platform: zml.Platform,
|
||||
llama: LlamaLM,
|
||||
llama_weights: zml.Bufferized(LlamaLM),
|
||||
buffer_store: zml.aio.BufferStore,
|
||||
) !void {
|
||||
try zml.testing.testLayer(platform, buffer_store, "embed_tokens", llama.model.embed_tokens, llama_weights.model.embed_tokens, 1e-3);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.self_attn.v_proj", llama.model.layers[0].self_attn.v_proj, llama_weights.model.layers[0].self_attn.v_proj, 1e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.self_attn.q_proj", llama.model.layers[0].self_attn.q_proj, llama_weights.model.layers[0].self_attn.q_proj, 2e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.self_attn.k_proj", llama.model.layers[0].self_attn.k_proj, llama_weights.model.layers[0].self_attn.k_proj, 2e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.self_attn.o_proj", llama.model.layers[0].self_attn.o_proj, llama_weights.model.layers[0].self_attn.o_proj, 2e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.mlp", llama.model.layers[0].mlp, llama_weights.model.layers[0].mlp, 1e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.input_layernorm", llama.model.layers[0].input_layernorm, llama_weights.model.layers[0].input_layernorm, 1e-2);
|
||||
try zml.testing.testLayer(platform, buffer_store, "layers.0.post_attention_layernorm", llama.model.layers[0].post_attention_layernorm, llama_weights.model.layers[0].post_attention_layernorm, 1e-2);
|
||||
|
||||
{
|
||||
const test_case = "layers.0.self_attn";
|
||||
std.log.info("Testing {s}", .{test_case});
|
||||
// Small wrapper to explicitly tag the input, and ignore the extra arguments used in HF implementation.
|
||||
const SelfAttnPrefill = struct {
|
||||
inner: llama_mod.SelfAttn,
|
||||
|
||||
pub fn forward(self: @This(), x_: Tensor) struct { Tensor, llama_mod.KvCache } {
|
||||
return self.inner.forward(x_.withTags(.{ .b, .s, .d }), null, null);
|
||||
}
|
||||
};
|
||||
|
||||
try zml.testing.testLayer(
|
||||
platform,
|
||||
buffer_store,
|
||||
"layers.0.self_attn",
|
||||
SelfAttnPrefill{ .inner = llama.model.layers[0].self_attn },
|
||||
.{ .inner = llama_weights.model.layers[0].self_attn },
|
||||
1e-3,
|
||||
);
|
||||
}
|
||||
}
|
||||
10
examples/loader/BUILD.bazel
Normal file
10
examples/loader/BUILD.bazel
Normal file
@ -0,0 +1,10 @@
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "safetensors",
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
72
examples/loader/main.zig
Normal file
72
examples/loader/main.zig
Normal file
@ -0,0 +1,72 @@
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
var args = std.process.args();
|
||||
// Skip executable path
|
||||
_ = args.next().?;
|
||||
|
||||
const file = if (args.next()) |path| blk: {
|
||||
std.debug.print("File path: {s}\n", .{path});
|
||||
break :blk path;
|
||||
} else {
|
||||
std.debug.print("Missing file path argument\n", .{});
|
||||
std.debug.print("Try: bazel run -c opt //loader:safetensors -- /path/to/mymodel.safetensors or /path/to/model.safetensors.index.json \n", .{});
|
||||
std.process.exit(0);
|
||||
};
|
||||
|
||||
var buffer_store = try zml.aio.safetensors.open(allocator, file);
|
||||
defer buffer_store.deinit();
|
||||
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
const platform = context.autoPlatform();
|
||||
const devices = platform.getDevices();
|
||||
|
||||
for (devices) |device| {
|
||||
std.debug.print("Device visible: {s}\n", .{device.getDescription(platform.pjrt_api).debugString(platform.pjrt_api)});
|
||||
}
|
||||
|
||||
var buffers = try gpa.allocator().alloc(zml.Buffer, buffer_store.buffers.count());
|
||||
defer {
|
||||
for (buffers) |*buf| {
|
||||
buf.deinit();
|
||||
}
|
||||
gpa.allocator().free(buffers);
|
||||
}
|
||||
|
||||
var total_bytes: usize = 0;
|
||||
var timer = try std.time.Timer.start();
|
||||
|
||||
var it = buffer_store.buffers.iterator();
|
||||
var i: usize = 0;
|
||||
std.debug.print("\nStart to read {d} buffers from store..\n", .{buffer_store.buffers.count()});
|
||||
|
||||
while (it.next()) |entry| : (i += 1) {
|
||||
const host_buffer = entry.value_ptr.*;
|
||||
total_bytes += host_buffer.data.len;
|
||||
std.debug.print("Buffer: {any} / {any}\n", .{ i + 1, buffer_store.buffers.count() });
|
||||
buffers[i] = try zml.Buffer.from(platform, host_buffer);
|
||||
}
|
||||
|
||||
const stop = timer.read();
|
||||
const time_in_s = zml.meta.divFloat(f64, stop, std.time.ns_per_s);
|
||||
const mbs = zml.meta.divFloat(f64, total_bytes, 1024 * 1024);
|
||||
|
||||
std.debug.print("\nLoading speed: {d:.2} MB/s\n\n", .{mbs / time_in_s});
|
||||
}
|
||||
93
examples/mnist/BUILD.bazel
Normal file
93
examples/mnist/BUILD.bazel
Normal file
@ -0,0 +1,93 @@
|
||||
load("@aspect_bazel_lib//lib:expand_template.bzl", "expand_template")
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
load("@aspect_bazel_lib//lib:transitions.bzl", "platform_transition_filegroup")
|
||||
load("@rules_oci//oci:defs.bzl", "oci_image", "oci_load", "oci_push")
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
# Executable
|
||||
zig_cc_binary(
|
||||
name = "mnist",
|
||||
args = [
|
||||
"$(location @com_github_ggerganov_ggml_mnist//file)",
|
||||
"$(location @com_github_ggerganov_ggml_mnist_data//file)",
|
||||
],
|
||||
data = [
|
||||
"@com_github_ggerganov_ggml_mnist//file",
|
||||
"@com_github_ggerganov_ggml_mnist_data//file",
|
||||
],
|
||||
main = "mnist.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":mnist"],
|
||||
)
|
||||
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":mnist"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
|
||||
expand_template(
|
||||
name = "entrypoint",
|
||||
data = [
|
||||
":mnist",
|
||||
"@com_github_ggerganov_ggml_mnist//file",
|
||||
"@com_github_ggerganov_ggml_mnist_data//file",
|
||||
],
|
||||
substitutions = {
|
||||
":model": "$(rlocationpath @com_github_ggerganov_ggml_mnist//file)",
|
||||
":data": "$(rlocationpath @com_github_ggerganov_ggml_mnist_data//file)",
|
||||
},
|
||||
template = [
|
||||
"./{}/mnist".format(package_name()),
|
||||
"./{}/mnist.runfiles/:model".format(package_name()),
|
||||
"./{}/mnist.runfiles/:data".format(package_name()),
|
||||
],
|
||||
)
|
||||
|
||||
oci_image(
|
||||
name = "image_",
|
||||
base = "@distroless_cc_debian12",
|
||||
entrypoint = ":entrypoint",
|
||||
tars = [":archive"],
|
||||
)
|
||||
|
||||
platform_transition_filegroup(
|
||||
name = "image",
|
||||
srcs = [":image_"],
|
||||
target_platform = "@zml//platforms:linux_amd64",
|
||||
)
|
||||
|
||||
oci_load(
|
||||
name = "load",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/mnist:latest",
|
||||
],
|
||||
)
|
||||
|
||||
oci_push(
|
||||
name = "push",
|
||||
image = ":image",
|
||||
remote_tags = ["latest"],
|
||||
repository = "index.docker.io/steeve/mnist",
|
||||
)
|
||||
|
||||
oci_load(
|
||||
name = "debug_image",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/mnist:latest",
|
||||
],
|
||||
)
|
||||
267
examples/mnist/mnist.zig
Normal file
267
examples/mnist/mnist.zig
Normal file
@ -0,0 +1,267 @@
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
const show_mlir = true;
|
||||
|
||||
/// Model definition
|
||||
const Mnist = struct {
|
||||
fc1: Layer,
|
||||
fc2: Layer,
|
||||
|
||||
const Layer = struct {
|
||||
weight: zml.Tensor,
|
||||
bias: zml.Tensor,
|
||||
|
||||
pub fn forward(self: Layer, input: zml.Tensor) zml.Tensor {
|
||||
return self.weight.matmul(input).add(self.bias).relu();
|
||||
}
|
||||
};
|
||||
|
||||
/// just two linear layers + relu activation
|
||||
pub fn forward(self: Mnist, input: zml.Tensor) zml.Tensor {
|
||||
// std.log.info("Compiling for target: {s}", .{@tagName(input.getContext().target())});
|
||||
var x = input.flattenAll().convert(.f32);
|
||||
const layers: []const Layer = &.{ self.fc1, self.fc2 };
|
||||
for (layers) |layer| {
|
||||
x = zml.call(layer, .forward, .{x});
|
||||
}
|
||||
return x.argMax(0, .u8).indices;
|
||||
}
|
||||
};
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
try asynk.AsyncThread.main(allocator, asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Create ZML context
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
std.debug.print("\n===========================\n== ZML MNIST Example ==\n===========================\n\n", .{});
|
||||
|
||||
// Auto-select platform
|
||||
const platform = context.autoPlatform();
|
||||
{
|
||||
// List available targets
|
||||
std.debug.print("Available Platforms:\n", .{});
|
||||
const selected_prefix = "✅";
|
||||
const not_selected_prefix = "• ";
|
||||
const selected_postfix = "(AUTO-SELECTED)\n";
|
||||
const not_selected_postfix = "\n";
|
||||
for (zml.platform.available_targets) |target| {
|
||||
std.debug.print(" {s} {s} {s}", .{
|
||||
if (target == platform.target) selected_prefix else not_selected_prefix,
|
||||
@tagName(target),
|
||||
if (target == platform.target) selected_postfix else not_selected_postfix,
|
||||
});
|
||||
|
||||
// now the platform's devices
|
||||
if (context.platforms.get(target)) |pfm| {
|
||||
for (pfm.getDevices(), 0..) |device, index| {
|
||||
const deviceKind = device.getDescription(platform.pjrt_api).getKind(platform.pjrt_api);
|
||||
std.debug.print(" ◦ #{d}: {s}\n", .{
|
||||
index,
|
||||
deviceKind,
|
||||
});
|
||||
// we only list 1 CPU device
|
||||
if (target == .cpu) break;
|
||||
}
|
||||
}
|
||||
}
|
||||
std.debug.print("\n", .{});
|
||||
}
|
||||
|
||||
// Parse program args
|
||||
const process_args = try std.process.argsAlloc(allocator);
|
||||
defer std.process.argsFree(allocator, process_args);
|
||||
const pt_model = process_args[1];
|
||||
const t10kfilename = process_args[2];
|
||||
|
||||
// Memory arena dedicated to model shapes and weights
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const arena = arena_state.allocator();
|
||||
|
||||
// Read model shapes.
|
||||
// Note this works because Mnist struct uses the same layer names as the pytorch model
|
||||
var buffer_store = try zml.aio.torch.open(allocator, pt_model);
|
||||
defer buffer_store.deinit();
|
||||
|
||||
const mnist_model = try zml.aio.populateModel(Mnist, allocator, buffer_store);
|
||||
std.debug.print("✅ Read model shapes from PyTorch file {s}\n", .{pt_model});
|
||||
|
||||
// Start loading weights
|
||||
var model_weights = try zml.aio.loadModelBuffers(Mnist, mnist_model, buffer_store, arena, platform);
|
||||
defer zml.aio.unloadBuffers(&model_weights);
|
||||
|
||||
// Start compiling
|
||||
const comp_start_time = std.time.milliTimestamp();
|
||||
if (show_mlir) {
|
||||
std.debug.print("\nCompiling model to MLIR....\n", .{});
|
||||
std.debug.print("-" ** 160 ++ "\n", .{});
|
||||
} else {
|
||||
std.debug.print("Compiling model to MLIR....\r", .{});
|
||||
}
|
||||
var compilation = try async_(zml.compile, .{ allocator, Mnist, .{}, .forward, .{zml.Shape.init(.{ 28, 28 }, .u8)}, buffer_store, platform });
|
||||
|
||||
// Wait for end of compilation and end of weights loading.
|
||||
const compiled_mnist = try compilation.await_();
|
||||
const comp_end_time = std.time.milliTimestamp();
|
||||
if (show_mlir) std.debug.print("-" ** 160 ++ "\n", .{});
|
||||
std.debug.print("✅ Compiled MNIST model in {d} milliseconds! \n", .{comp_end_time - comp_start_time});
|
||||
|
||||
// send weights to accelerator / GPU
|
||||
var mnist = try compiled_mnist.prepare(allocator, model_weights);
|
||||
defer mnist.deinit();
|
||||
std.debug.print("✅ Weights transferred, starting inference...\n\n", .{});
|
||||
|
||||
// Load a random digit image from the dataset.
|
||||
const dataset = try asynk.File.open(t10kfilename, .{ .mode = .read_only });
|
||||
defer dataset.close() catch unreachable;
|
||||
var rng = std.Random.Xoshiro256.init(@intCast(std.time.timestamp()));
|
||||
|
||||
// inference - can be looped
|
||||
{
|
||||
const idx = rng.random().intRangeAtMost(u64, 0, 10000 - 1);
|
||||
var sample: [28 * 28]u8 align(16) = undefined;
|
||||
_ = try dataset.pread(&sample, 16 + (idx * 28 * 28));
|
||||
var input = try zml.Buffer.from(platform, zml.HostBuffer.fromBytes(zml.Shape.init(.{ 28, 28 }, .u8), &sample));
|
||||
defer input.deinit();
|
||||
|
||||
printDigit(sample);
|
||||
var result: zml.Buffer = mnist.call(.{input});
|
||||
defer result.deinit();
|
||||
|
||||
std.debug.print("\n✅ RECOGNIZED DIGIT:\n", .{});
|
||||
std.debug.print(" +-------------+\n", .{});
|
||||
std.debug.print("{s}\n", .{digits[try result.getValue(u8)]});
|
||||
std.debug.print(" +-------------+\n\n", .{});
|
||||
}
|
||||
}
|
||||
|
||||
fn printDigit(digit: [28 * 28]u8) void {
|
||||
var buffer: [28][30][2]u8 = undefined;
|
||||
std.debug.print(" R E C O G N I Z I N G I N P U T I M A G E :\n", .{});
|
||||
std.debug.print("+---------------------------------------------------------+\n", .{});
|
||||
for (0..28) |y| {
|
||||
buffer[y][0] = .{ '|', ' ' };
|
||||
buffer[y][29] = .{ '|', '\n' };
|
||||
for (1..29) |x| {
|
||||
const idx = (y * 28) + (x - 1);
|
||||
const val = digit[idx];
|
||||
buffer[y][x] = blk: {
|
||||
if (val > 240) break :blk .{ '*', '*' };
|
||||
if (val > 225) break :blk .{ 'o', 'o' };
|
||||
if (val > 210) break :blk .{ '.', '.' };
|
||||
break :blk .{ ' ', ' ' };
|
||||
};
|
||||
}
|
||||
}
|
||||
std.fmt.format(asynk.StdOut().writer(), "{s}", .{std.mem.asBytes(&buffer)}) catch unreachable;
|
||||
std.debug.print("+---------------------------------------------------------+\n", .{});
|
||||
}
|
||||
|
||||
const digits = [_][]const u8{
|
||||
\\ | ### |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ### |
|
||||
,
|
||||
\\ | # |
|
||||
\\ | ## |
|
||||
\\ | # # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | ##### |
|
||||
,
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # |
|
||||
\\ | ##### |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | ####### |
|
||||
,
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # |
|
||||
\\ | ##### |
|
||||
\\ | # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
,
|
||||
\\ | # |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ####### |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
,
|
||||
\\ | ####### |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | ###### |
|
||||
\\ | # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
,
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # |
|
||||
\\ | ###### |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
,
|
||||
\\ | ####### |
|
||||
\\ | # # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
\\ | # |
|
||||
,
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
,
|
||||
\\ | ##### |
|
||||
\\ | # # |
|
||||
\\ | # # |
|
||||
\\ | ###### |
|
||||
\\ | # |
|
||||
\\ | # # |
|
||||
\\ | ##### |
|
||||
,
|
||||
};
|
||||
|
||||
pub const std_options = .{
|
||||
// Set the global log level to err
|
||||
.log_level = .err,
|
||||
.log_scope_levels = &[_]std.log.ScopeLevel{
|
||||
.{ .scope = .pjrt, .level = .err },
|
||||
.{ .scope = .zml_module, .level = if (show_mlir) .debug else .err },
|
||||
},
|
||||
};
|
||||
21
examples/platform_mappings
Normal file
21
examples/platform_mappings
Normal file
@ -0,0 +1,21 @@
|
||||
platforms:
|
||||
@zml//platforms:linux_amd64
|
||||
--cpu=k8
|
||||
|
||||
@zml//platforms:linux_arm64
|
||||
--cpu=aarch64
|
||||
|
||||
@zml//platforms:macos_arm64
|
||||
--cpu=darwin_arm64
|
||||
--apple_platform_type=macos
|
||||
|
||||
flags:
|
||||
--cpu=darwin_arm64
|
||||
--apple_platform_type=macos
|
||||
@zml//platforms:macos_arm64
|
||||
|
||||
--cpu=k8
|
||||
@zml//platforms:linux_amd64
|
||||
|
||||
--cpu=aarch64
|
||||
@zml//platforms:linux_arm64
|
||||
64
examples/simple_layer/BUILD.bazel
Normal file
64
examples/simple_layer/BUILD.bazel
Normal file
@ -0,0 +1,64 @@
|
||||
load("@aspect_bazel_lib//lib:tar.bzl", "mtree_spec", "tar")
|
||||
load("@aspect_bazel_lib//lib:transitions.bzl", "platform_transition_filegroup")
|
||||
load("@rules_oci//oci:defs.bzl", "oci_image", "oci_load", "oci_push")
|
||||
load("@zml//bazel:zig.bzl", "zig_cc_binary")
|
||||
|
||||
zig_cc_binary(
|
||||
name = "simple_layer",
|
||||
main = "main.zig",
|
||||
deps = [
|
||||
"@zml//async",
|
||||
"@zml//zml",
|
||||
],
|
||||
)
|
||||
|
||||
# Manifest created from the simple_layer binary and friends
|
||||
mtree_spec(
|
||||
name = "mtree",
|
||||
srcs = [":simple_layer"],
|
||||
)
|
||||
|
||||
# Create a tar archive from the above manifest
|
||||
tar(
|
||||
name = "archive",
|
||||
srcs = [":simple_layer"],
|
||||
args = [
|
||||
"--options",
|
||||
"zstd:compression-level=9",
|
||||
],
|
||||
compress = "zstd",
|
||||
mtree = ":mtree",
|
||||
)
|
||||
|
||||
# The actual docker image, with entrypoint, created from tar archive
|
||||
oci_image(
|
||||
name = "image_",
|
||||
base = "@distroless_cc_debian12",
|
||||
entrypoint = ["./{}/simple_layer".format(package_name())],
|
||||
tars = [":archive"],
|
||||
)
|
||||
|
||||
# We always want to create the image for Linux
|
||||
platform_transition_filegroup(
|
||||
name = "image",
|
||||
srcs = [":image_"],
|
||||
target_platform = "@zml//platforms:linux_amd64",
|
||||
)
|
||||
|
||||
# Load will immediatly load the image (eg: docker load)
|
||||
oci_load(
|
||||
name = "load",
|
||||
image = ":image",
|
||||
repo_tags = [
|
||||
"distroless/simple_layer:latest",
|
||||
],
|
||||
)
|
||||
|
||||
# Bazel target for pushing the Linux image to the docker registry
|
||||
oci_push(
|
||||
name = "push",
|
||||
image = ":image",
|
||||
remote_tags = ["latest"],
|
||||
# override with -- --repository foo.bar/org/image
|
||||
repository = "index.docker.io/renerocksai/simple_layer",
|
||||
)
|
||||
99
examples/simple_layer/main.zig
Normal file
99
examples/simple_layer/main.zig
Normal file
@ -0,0 +1,99 @@
|
||||
const std = @import("std");
|
||||
const zml = @import("zml");
|
||||
const asynk = @import("async");
|
||||
|
||||
const async_ = asynk.async_;
|
||||
|
||||
/// Model definition
|
||||
const Layer = struct {
|
||||
bias: ?zml.Tensor = null,
|
||||
weight: zml.Tensor,
|
||||
|
||||
pub fn forward(self: Layer, x: zml.Tensor) zml.Tensor {
|
||||
var y = self.weight.mul(x);
|
||||
if (self.bias) |bias| {
|
||||
y = y.add(bias);
|
||||
}
|
||||
return y;
|
||||
}
|
||||
};
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
try asynk.AsyncThread.main(gpa.allocator(), asyncMain, .{});
|
||||
}
|
||||
|
||||
pub fn asyncMain() !void {
|
||||
// Short lived allocations
|
||||
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
defer _ = gpa.deinit();
|
||||
const allocator = gpa.allocator();
|
||||
|
||||
// Arena allocator for BufferStore etc.
|
||||
var arena_state = std.heap.ArenaAllocator.init(allocator);
|
||||
defer arena_state.deinit();
|
||||
const arena = arena_state.allocator();
|
||||
|
||||
var context = try zml.Context.init();
|
||||
defer context.deinit();
|
||||
|
||||
const platform = context.autoPlatform();
|
||||
|
||||
// Our weights and bias to use
|
||||
var weights = [3]f16{ 2.0, 2.0, 2.0 };
|
||||
var bias = [3]f16{ 1.0, 2.0, 3.0 };
|
||||
const input_shape = zml.Shape.init(.{3}, .f16);
|
||||
|
||||
// We manually produce a BufferStore. You would not normally do that.
|
||||
// A BufferStore is usually created by loading model data from a file.
|
||||
var buffers: zml.aio.BufferStore.Buffers = .{};
|
||||
try buffers.put(arena, "weight", zml.HostBuffer.fromArray(&weights));
|
||||
try buffers.put(arena, "bias", zml.HostBuffer.fromArray(&bias));
|
||||
|
||||
// the actual BufferStore
|
||||
const buffer_store: zml.aio.BufferStore = .{
|
||||
.arena = arena_state,
|
||||
.buffers = buffers,
|
||||
};
|
||||
|
||||
// A clone of our model, consisting of shapes. We only need shapes for compiling.
|
||||
// We use the BufferStore to infer the shapes.
|
||||
const model_shapes = try zml.aio.populateModel(Layer, allocator, buffer_store);
|
||||
|
||||
// Start compiling. This uses the inferred shapes from the BufferStore.
|
||||
// The shape of the input tensor, we have to pass in manually.
|
||||
var compilation = try async_(zml.compileModel, .{ allocator, model_shapes, .forward, .{input_shape}, platform });
|
||||
|
||||
// Produce a bufferized weights struct from the fake BufferStore.
|
||||
// This is like the inferred shapes, but with actual values.
|
||||
// We will need to send those to the computation device later.
|
||||
var model_weights = try zml.aio.loadBuffers(Layer, .{}, buffer_store, arena, platform);
|
||||
defer zml.aio.unloadBuffers(&model_weights); // for good practice
|
||||
|
||||
// Wait for compilation to finish
|
||||
const compiled = try compilation.await_();
|
||||
|
||||
// pass the model weights to the compiled module to create an executable module
|
||||
var executable = try compiled.prepare(arena, model_weights);
|
||||
defer executable.deinit();
|
||||
|
||||
// prepare an input buffer
|
||||
// Here, we use zml.HostBuffer.fromSlice to show how you would create a HostBuffer
|
||||
// with a specific shape from an array.
|
||||
// For situations where e.g. you have an [4]f16 array but need a .{2, 2} input shape.
|
||||
var input = [3]f16{ 5.0, 5.0, 5.0 };
|
||||
var input_buffer = try zml.Buffer.from(platform, zml.HostBuffer.fromSlice(input_shape, &input));
|
||||
defer input_buffer.deinit();
|
||||
|
||||
// call our executable module
|
||||
var result: zml.Buffer = executable.call(.{input_buffer});
|
||||
defer result.deinit();
|
||||
|
||||
// fetch the result to CPU memory
|
||||
const cpu_result = try result.toHostAlloc(arena);
|
||||
std.debug.print(
|
||||
"\nThe result of {d} * {d} + {d} = {d}\n",
|
||||
.{ &weights, &input, &bias, cpu_result.items(f16) },
|
||||
);
|
||||
}
|
||||
11
examples/third_party/tigerbeetle/BUILD.bazel
vendored
Normal file
11
examples/third_party/tigerbeetle/BUILD.bazel
vendored
Normal file
@ -0,0 +1,11 @@
|
||||
# Files in this folder come from the very fine folks of TigerBeetle
|
||||
# and is licensed under Apache 2.0 attribution license.
|
||||
# https://github.com/tigerbeetle/tigerbeetle
|
||||
load("@rules_zig//zig:defs.bzl", "zig_library")
|
||||
|
||||
zig_library(
|
||||
name = "flags",
|
||||
import_name = "tigerbeetle/flags",
|
||||
main = "flags.zig",
|
||||
visibility = ["//visibility:public"],
|
||||
)
|
||||
661
examples/third_party/tigerbeetle/flags.zig
vendored
Normal file
661
examples/third_party/tigerbeetle/flags.zig
vendored
Normal file
@ -0,0 +1,661 @@
|
||||
//! From TigerBeetle, under Apache 2.0 attribution license.
|
||||
//! https://github.com/tigerbeetle/tigerbeetle/blob/main/src/flags.zig TigerBeetle/
|
||||
//!
|
||||
//! The purpose of `flags` is to define standard behavior for parsing CLI arguments and provide
|
||||
//! a specific parsing library, implementing this behavior.
|
||||
//!
|
||||
//! These are TigerBeetle CLI guidelines:
|
||||
//!
|
||||
//! - The main principle is robustness --- make operator errors harder to make.
|
||||
//! - For production usage, avoid defaults.
|
||||
//! - Thoroughly validate options.
|
||||
//! - In particular, check that no options are repeated.
|
||||
//! - Use only long options (`--addresses`).
|
||||
//! - Exception: `-h/--help` is allowed.
|
||||
//! - Use `--key=value` syntax for an option with an argument.
|
||||
//! Don't use `--key value`, as that can be ambiguous (e.g., `--key --verbose`).
|
||||
//! - Use subcommand syntax when appropriate.
|
||||
//! - Use positional arguments when appropriate.
|
||||
//!
|
||||
//! Design choices for this particular `flags` library:
|
||||
//!
|
||||
//! - Be a 80% solution. Parsing arguments is a surprisingly vast topic: auto-generated help,
|
||||
//! bash completions, typo correction. Rather than providing a definitive solution, `flags`
|
||||
//! is just one possible option. It is ok to re-implement arg parsing in a different way, as long
|
||||
//! as the CLI guidelines are observed.
|
||||
//!
|
||||
//! - No auto-generated help. Zig doesn't expose doc comments through `@typeInfo`, so its hard to
|
||||
//! implement auto-help nicely. Additionally, fully hand-crafted `--help` message can be of
|
||||
//! higher quality.
|
||||
//!
|
||||
//! - Fatal errors. It might be "cleaner" to use `try` to propagate the error to the caller, but
|
||||
//! during early CLI parsing, it is much simpler to terminate the process directly and save the
|
||||
//! caller the hassle of propagating errors. The `fatal` function is public, to allow the caller
|
||||
//! to run additional validation or parsing using the same error reporting mechanism.
|
||||
//!
|
||||
//! - Concise DSL. Most cli parsing is done for ad-hoc tools like benchmarking, where the ability to
|
||||
//! quickly add a new argument is valuable. As this is a 80% solution, production code may use
|
||||
//! more verbose approach if it gives better UX.
|
||||
//!
|
||||
//! - Caller manages ArgsIterator. ArgsIterator owns the backing memory of the args, so we let the
|
||||
//! caller to manage the lifetime. The caller should be skipping program name.
|
||||
|
||||
const std = @import("std");
|
||||
const builtin = @import("builtin");
|
||||
const assert = std.debug.assert;
|
||||
|
||||
/// Format and print an error message to stderr, then exit with an exit code of 1.
|
||||
pub fn fatal(comptime fmt_string: []const u8, args: anytype) noreturn {
|
||||
const stderr = std.io.getStdErr().writer();
|
||||
stderr.print("error: " ++ fmt_string ++ "\n", args) catch {};
|
||||
std.posix.exit(1);
|
||||
}
|
||||
|
||||
/// Parse CLI arguments for subcommands specified as Zig `struct` or `union(enum)`:
|
||||
///
|
||||
/// ```
|
||||
/// const CliArgs = union(enum) {
|
||||
/// start: struct { addresses: []const u8, replica: u32 },
|
||||
/// format: struct {
|
||||
/// verbose: bool = false,
|
||||
/// positional: struct {
|
||||
/// path: []const u8,
|
||||
/// }
|
||||
/// },
|
||||
///
|
||||
/// pub const help =
|
||||
/// \\ tigerbeetle start --addresses=<addresses> --replica=<replica>
|
||||
/// \\ tigerbeetle format [--verbose] <path>
|
||||
/// }
|
||||
///
|
||||
/// const cli_args = parse_commands(&args, CliArgs);
|
||||
/// ```
|
||||
///
|
||||
/// `positional` field is treated specially, it designates positional arguments.
|
||||
///
|
||||
/// If `pub const help` declaration is present, it is used to implement `-h/--help` argument.
|
||||
pub fn parse(args: *std.process.ArgIterator, comptime CliArgs: type) CliArgs {
|
||||
assert(args.skip()); // Discard executable name.
|
||||
|
||||
return switch (@typeInfo(CliArgs)) {
|
||||
.Union => parse_commands(args, CliArgs),
|
||||
.Struct => parse_flags(args, CliArgs),
|
||||
else => unreachable,
|
||||
};
|
||||
}
|
||||
|
||||
fn parse_commands(args: *std.process.ArgIterator, comptime Commands: type) Commands {
|
||||
comptime assert(@typeInfo(Commands) == .Union);
|
||||
comptime assert(std.meta.fields(Commands).len >= 2);
|
||||
|
||||
const first_arg = args.next() orelse fatal(
|
||||
"subcommand required, expected {s}",
|
||||
.{comptime fields_to_comma_list(Commands)},
|
||||
);
|
||||
|
||||
// NB: help must be declared as *pub* const to be visible here.
|
||||
if (@hasDecl(Commands, "help")) {
|
||||
if (std.mem.eql(u8, first_arg, "-h") or std.mem.eql(u8, first_arg, "--help")) {
|
||||
std.io.getStdOut().writeAll(Commands.help) catch std.posix.exit(1);
|
||||
std.posix.exit(0);
|
||||
}
|
||||
}
|
||||
|
||||
inline for (comptime std.meta.fields(Commands)) |field| {
|
||||
comptime assert(std.mem.indexOf(u8, field.name, "_") == null);
|
||||
if (std.mem.eql(u8, first_arg, field.name)) {
|
||||
return @unionInit(Commands, field.name, parse_flags(args, field.type));
|
||||
}
|
||||
}
|
||||
fatal("unknown subcommand: '{s}'", .{first_arg});
|
||||
}
|
||||
|
||||
fn parse_flags(args: *std.process.ArgIterator, comptime Flags: type) Flags {
|
||||
@setEvalBranchQuota(5_000);
|
||||
|
||||
if (Flags == void) {
|
||||
if (args.next()) |arg| {
|
||||
fatal("unexpected argument: '{s}'", .{arg});
|
||||
}
|
||||
return {};
|
||||
}
|
||||
|
||||
assert(@typeInfo(Flags) == .Struct);
|
||||
|
||||
comptime var fields: [std.meta.fields(Flags).len]std.builtin.Type.StructField = undefined;
|
||||
comptime var field_count = 0;
|
||||
|
||||
comptime var positional_fields: []const std.builtin.Type.StructField = &.{};
|
||||
|
||||
comptime for (std.meta.fields(Flags)) |field| {
|
||||
if (std.mem.eql(u8, field.name, "positional")) {
|
||||
assert(@typeInfo(field.type) == .Struct);
|
||||
positional_fields = std.meta.fields(field.type);
|
||||
var optional_tail = false;
|
||||
for (positional_fields) |positional_field| {
|
||||
if (default_value(positional_field) == null) {
|
||||
if (optional_tail) @panic("optional positional arguments must be last");
|
||||
} else {
|
||||
optional_tail = true;
|
||||
}
|
||||
switch (@typeInfo(positional_field.type)) {
|
||||
.Optional => |optional| {
|
||||
// optional flags should have a default
|
||||
assert(default_value(positional_field) != null);
|
||||
assert(default_value(positional_field).? == null);
|
||||
assert_valid_value_type(optional.child);
|
||||
},
|
||||
else => {
|
||||
assert_valid_value_type(positional_field.type);
|
||||
},
|
||||
}
|
||||
}
|
||||
} else {
|
||||
fields[field_count] = field;
|
||||
field_count += 1;
|
||||
|
||||
switch (@typeInfo(field.type)) {
|
||||
.Bool => {
|
||||
// boolean flags should have a default
|
||||
assert(default_value(field) != null);
|
||||
assert(default_value(field).? == false);
|
||||
},
|
||||
.Optional => |optional| {
|
||||
// optional flags should have a default
|
||||
assert(default_value(field) != null);
|
||||
assert(default_value(field).? == null);
|
||||
|
||||
assert_valid_value_type(optional.child);
|
||||
},
|
||||
else => {
|
||||
assert_valid_value_type(field.type);
|
||||
},
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
var result: Flags = undefined;
|
||||
// Would use std.enums.EnumFieldStruct(Flags, u32, 0) here but Flags is a Struct not an Enum.
|
||||
var counts = comptime blk: {
|
||||
var count_fields = std.meta.fields(Flags)[0..std.meta.fields(Flags).len].*;
|
||||
for (&count_fields) |*field| {
|
||||
field.type = u32;
|
||||
field.alignment = @alignOf(u32);
|
||||
field.default_value = @ptrCast(&@as(u32, 0));
|
||||
}
|
||||
break :blk @Type(.{ .Struct = .{
|
||||
.layout = .auto,
|
||||
.fields = &count_fields,
|
||||
.decls = &.{},
|
||||
.is_tuple = false,
|
||||
} }){};
|
||||
};
|
||||
|
||||
// When parsing arguments, we must consider longer arguments first, such that `--foo-bar=92` is
|
||||
// not confused for a misspelled `--foo=92`. Using `std.sort` for comptime-only values does not
|
||||
// work, so open-code insertion sort, and comptime assert order during the actual parsing.
|
||||
comptime {
|
||||
for (fields[0..field_count], 0..) |*field_right, i| {
|
||||
for (fields[0..i]) |*field_left| {
|
||||
if (field_left.name.len < field_right.name.len) {
|
||||
std.mem.swap(std.builtin.Type.StructField, field_left, field_right);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
var parsed_positional = false;
|
||||
next_arg: while (args.next()) |arg| {
|
||||
comptime var field_len_prev = std.math.maxInt(usize);
|
||||
inline for (fields[0..field_count]) |field| {
|
||||
const flag = comptime flag_name(field);
|
||||
|
||||
comptime assert(field_len_prev >= field.name.len);
|
||||
field_len_prev = field.name.len;
|
||||
if (std.mem.startsWith(u8, arg, flag)) {
|
||||
if (parsed_positional) {
|
||||
fatal("unexpected trailing option: '{s}'", .{arg});
|
||||
}
|
||||
|
||||
@field(counts, field.name) += 1;
|
||||
const flag_value = parse_flag(field.type, flag, arg);
|
||||
@field(result, field.name) = flag_value;
|
||||
continue :next_arg;
|
||||
}
|
||||
}
|
||||
|
||||
if (@hasField(Flags, "positional")) {
|
||||
counts.positional += 1;
|
||||
switch (counts.positional - 1) {
|
||||
inline 0...positional_fields.len - 1 => |positional_index| {
|
||||
const positional_field = positional_fields[positional_index];
|
||||
const flag = comptime flag_name_positional(positional_field);
|
||||
|
||||
if (arg.len == 0) fatal("{s}: empty argument", .{flag});
|
||||
// Prevent ambiguity between a flag and positional argument value. We could add
|
||||
// support for bare ` -- ` as a disambiguation mechanism once we have a real
|
||||
// use-case.
|
||||
if (arg[0] == '-') fatal("unexpected argument: '{s}'", .{arg});
|
||||
parsed_positional = true;
|
||||
|
||||
@field(result.positional, positional_field.name) =
|
||||
parse_value(positional_field.type, flag, arg);
|
||||
continue :next_arg;
|
||||
},
|
||||
else => {}, // Fall-through to the unexpected argument error.
|
||||
}
|
||||
}
|
||||
|
||||
fatal("unexpected argument: '{s}'", .{arg});
|
||||
}
|
||||
|
||||
inline for (fields[0..field_count]) |field| {
|
||||
const flag = flag_name(field);
|
||||
switch (@field(counts, field.name)) {
|
||||
0 => if (default_value(field)) |default| {
|
||||
@field(result, field.name) = default;
|
||||
} else {
|
||||
fatal("{s}: argument is required", .{flag});
|
||||
},
|
||||
1 => {},
|
||||
else => fatal("{s}: duplicate argument", .{flag}),
|
||||
}
|
||||
}
|
||||
|
||||
if (@hasField(Flags, "positional")) {
|
||||
assert(counts.positional <= positional_fields.len);
|
||||
inline for (positional_fields, 0..) |positional_field, positional_index| {
|
||||
if (positional_index >= counts.positional) {
|
||||
const flag = comptime flag_name_positional(positional_field);
|
||||
if (default_value(positional_field)) |default| {
|
||||
@field(result.positional, positional_field.name) = default;
|
||||
} else {
|
||||
fatal("{s}: argument is required", .{flag});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
fn assert_valid_value_type(comptime T: type) void {
|
||||
comptime {
|
||||
if (T == []const u8 or T == [:0]const u8 or T == ByteSize or @typeInfo(T) == .Int) return;
|
||||
|
||||
if (@typeInfo(T) == .Enum) {
|
||||
const info = @typeInfo(T).Enum;
|
||||
assert(info.is_exhaustive);
|
||||
assert(info.fields.len >= 2);
|
||||
return;
|
||||
}
|
||||
|
||||
@compileLog("unsupported type", T);
|
||||
unreachable;
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse, e.g., `--cluster=123` into `123` integer
|
||||
fn parse_flag(comptime T: type, flag: []const u8, arg: [:0]const u8) T {
|
||||
assert(flag[0] == '-' and flag[1] == '-');
|
||||
|
||||
if (T == bool) {
|
||||
if (!std.mem.eql(u8, arg, flag)) {
|
||||
fatal("{s}: argument does not require a value in '{s}'", .{ flag, arg });
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
const value = parse_flag_split_value(flag, arg);
|
||||
assert(value.len > 0);
|
||||
return parse_value(T, flag, value);
|
||||
}
|
||||
|
||||
/// Splits the value part from a `--arg=value` syntax.
|
||||
fn parse_flag_split_value(flag: []const u8, arg: [:0]const u8) [:0]const u8 {
|
||||
assert(flag[0] == '-' and flag[1] == '-');
|
||||
assert(std.mem.startsWith(u8, arg, flag));
|
||||
|
||||
const value = arg[flag.len..];
|
||||
if (value.len == 0) {
|
||||
fatal("{s}: expected value separator '='", .{flag});
|
||||
}
|
||||
if (value[0] != '=') {
|
||||
fatal(
|
||||
"{s}: expected value separator '=', but found '{c}' in '{s}'",
|
||||
.{ flag, value[0], arg },
|
||||
);
|
||||
}
|
||||
if (value.len == 1) fatal("{s}: argument requires a value", .{flag});
|
||||
return value[1..];
|
||||
}
|
||||
|
||||
fn parse_value(comptime T: type, flag: []const u8, value: [:0]const u8) T {
|
||||
comptime assert(T != bool);
|
||||
assert((flag[0] == '-' and flag[1] == '-') or flag[0] == '<');
|
||||
assert(value.len > 0);
|
||||
|
||||
const V = switch (@typeInfo(T)) {
|
||||
.Optional => |optional| optional.child,
|
||||
else => T,
|
||||
};
|
||||
|
||||
if (V == []const u8 or V == [:0]const u8) return value;
|
||||
if (V == ByteSize) return parse_value_size(flag, value);
|
||||
if (@typeInfo(V) == .Int) return parse_value_int(V, flag, value);
|
||||
if (@typeInfo(V) == .Enum) return parse_value_enum(V, flag, value);
|
||||
comptime unreachable;
|
||||
}
|
||||
|
||||
fn parse_value_size(flag: []const u8, value: []const u8) ByteSize {
|
||||
assert((flag[0] == '-' and flag[1] == '-') or flag[0] == '<');
|
||||
|
||||
return ByteSize.parse(value) catch |err| {
|
||||
switch (err) {
|
||||
error.ParseOverflow => fatal(
|
||||
"{s}: value exceeds 64-bit unsigned integer: '{s}'",
|
||||
.{ flag, value },
|
||||
),
|
||||
error.InvalidSize => fatal(
|
||||
"{s}: expected a size, but found '{s}'",
|
||||
.{ flag, value },
|
||||
),
|
||||
error.InvalidUnit => fatal(
|
||||
"{s}: invalid unit in size '{s}', (needed KiB, MiB, GiB or TiB)",
|
||||
.{ flag, value },
|
||||
),
|
||||
error.BytesOverflow => fatal(
|
||||
"{s}: size in bytes exceeds 64-bit unsigned integer: '{s}'",
|
||||
.{ flag, value },
|
||||
),
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
pub const ByteUnit = enum(u64) {
|
||||
bytes = 1,
|
||||
kib = 1024,
|
||||
mib = 1024 * 1024,
|
||||
gib = 1024 * 1024 * 1024,
|
||||
tib = 1024 * 1024 * 1024 * 1024,
|
||||
};
|
||||
|
||||
const ByteSizeParseError = error{
|
||||
ParseOverflow,
|
||||
InvalidSize,
|
||||
InvalidUnit,
|
||||
BytesOverflow,
|
||||
};
|
||||
|
||||
pub const ByteSize = struct {
|
||||
value: u64,
|
||||
unit: ByteUnit = .bytes,
|
||||
|
||||
fn parse(value: []const u8) ByteSizeParseError!ByteSize {
|
||||
assert(value.len != 0);
|
||||
|
||||
const split: struct {
|
||||
value_input: []const u8,
|
||||
unit_input: []const u8,
|
||||
} = split: for (0..value.len) |i| {
|
||||
if (!std.ascii.isDigit(value[i])) {
|
||||
break :split .{
|
||||
.value_input = value[0..i],
|
||||
.unit_input = value[i..],
|
||||
};
|
||||
}
|
||||
} else {
|
||||
break :split .{
|
||||
.value_input = value,
|
||||
.unit_input = "",
|
||||
};
|
||||
};
|
||||
|
||||
const amount = std.fmt.parseUnsigned(u64, split.value_input, 10) catch |err| {
|
||||
switch (err) {
|
||||
error.Overflow => {
|
||||
return ByteSizeParseError.ParseOverflow;
|
||||
},
|
||||
error.InvalidCharacter => {
|
||||
// The only case this can happen is for the empty string
|
||||
return ByteSizeParseError.InvalidSize;
|
||||
},
|
||||
}
|
||||
};
|
||||
|
||||
const unit = if (split.unit_input.len > 0)
|
||||
unit: inline for (comptime std.enums.values(ByteUnit)) |tag| {
|
||||
if (std.ascii.eqlIgnoreCase(split.unit_input, @tagName(tag))) {
|
||||
break :unit tag;
|
||||
}
|
||||
} else {
|
||||
return ByteSizeParseError.InvalidUnit;
|
||||
}
|
||||
else
|
||||
ByteUnit.bytes;
|
||||
|
||||
_ = std.math.mul(u64, amount, @intFromEnum(unit)) catch {
|
||||
return ByteSizeParseError.BytesOverflow;
|
||||
};
|
||||
|
||||
return ByteSize{ .value = amount, .unit = unit };
|
||||
}
|
||||
|
||||
pub fn bytes(size: *const ByteSize) u64 {
|
||||
return std.math.mul(
|
||||
u64,
|
||||
size.value,
|
||||
@intFromEnum(size.unit),
|
||||
) catch unreachable;
|
||||
}
|
||||
|
||||
pub fn suffix(size: *const ByteSize) []const u8 {
|
||||
return switch (size.unit) {
|
||||
.bytes => "",
|
||||
.kib => "KiB",
|
||||
.mib => "MiB",
|
||||
.gib => "GiB",
|
||||
.tib => "TiB",
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
test parse_value_size {
|
||||
const kib = 1024;
|
||||
const mib = kib * 1024;
|
||||
const gib = mib * 1024;
|
||||
const tib = gib * 1024;
|
||||
|
||||
const cases = .{
|
||||
.{ 0, "0", 0, ByteUnit.bytes },
|
||||
.{ 1, "1", 1, ByteUnit.bytes },
|
||||
.{ 140737488355328, "140737488355328", 140737488355328, ByteUnit.bytes },
|
||||
.{ 140737488355328, "128TiB", 128, ByteUnit.tib },
|
||||
.{ 1 * tib, "1TiB", 1, ByteUnit.tib },
|
||||
.{ 10 * tib, "10tib", 10, ByteUnit.tib },
|
||||
.{ 1 * gib, "1GiB", 1, ByteUnit.gib },
|
||||
.{ 10 * gib, "10gib", 10, ByteUnit.gib },
|
||||
.{ 1 * mib, "1MiB", 1, ByteUnit.mib },
|
||||
.{ 10 * mib, "10mib", 10, ByteUnit.mib },
|
||||
.{ 1 * kib, "1KiB", 1, ByteUnit.kib },
|
||||
.{ 10 * kib, "10kib", 10, ByteUnit.kib },
|
||||
};
|
||||
|
||||
inline for (cases) |case| {
|
||||
const bytes = case[0];
|
||||
const input = case[1];
|
||||
const unit_val = case[2];
|
||||
const unit = case[3];
|
||||
const got = parse_value_size("--size", input);
|
||||
assert(bytes == got.bytes());
|
||||
assert(unit_val == got.value);
|
||||
assert(unit == got.unit);
|
||||
}
|
||||
}
|
||||
|
||||
/// Parse string value into an integer, providing a nice error message for the user.
|
||||
fn parse_value_int(comptime T: type, flag: []const u8, value: [:0]const u8) T {
|
||||
assert((flag[0] == '-' and flag[1] == '-') or flag[0] == '<');
|
||||
|
||||
return std.fmt.parseInt(T, value, 10) catch |err| {
|
||||
switch (err) {
|
||||
error.Overflow => fatal(
|
||||
"{s}: value exceeds {d}-bit {s} integer: '{s}'",
|
||||
.{ flag, @typeInfo(T).Int.bits, @tagName(@typeInfo(T).Int.signedness), value },
|
||||
),
|
||||
error.InvalidCharacter => fatal(
|
||||
"{s}: expected an integer value, but found '{s}' (invalid digit)",
|
||||
.{ flag, value },
|
||||
),
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
fn parse_value_enum(comptime E: type, flag: []const u8, value: [:0]const u8) E {
|
||||
assert((flag[0] == '-' and flag[1] == '-') or flag[0] == '<');
|
||||
comptime assert(@typeInfo(E).Enum.is_exhaustive);
|
||||
|
||||
return std.meta.stringToEnum(E, value) orelse fatal(
|
||||
"{s}: expected one of {s}, but found '{s}'",
|
||||
.{ flag, comptime fields_to_comma_list(E), value },
|
||||
);
|
||||
}
|
||||
|
||||
fn fields_to_comma_list(comptime E: type) []const u8 {
|
||||
comptime {
|
||||
const field_count = std.meta.fields(E).len;
|
||||
assert(field_count >= 2);
|
||||
|
||||
var result: []const u8 = "";
|
||||
for (std.meta.fields(E), 0..) |field, field_index| {
|
||||
const separator = switch (field_index) {
|
||||
0 => "",
|
||||
else => ", ",
|
||||
field_count - 1 => if (field_count == 2) " or " else ", or ",
|
||||
};
|
||||
result = result ++ separator ++ "'" ++ field.name ++ "'";
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
|
||||
pub fn flag_name(comptime field: std.builtin.Type.StructField) []const u8 {
|
||||
// TODO(Zig): Cleanup when this is fixed after Zig 0.11.
|
||||
// Without comptime blk, the compiler thinks the result is a runtime slice returning a UAF.
|
||||
return comptime blk: {
|
||||
assert(!std.mem.eql(u8, field.name, "positional"));
|
||||
|
||||
var result: []const u8 = "--";
|
||||
var index = 0;
|
||||
while (std.mem.indexOf(u8, field.name[index..], "_")) |i| {
|
||||
result = result ++ field.name[index..][0..i] ++ "-";
|
||||
index = index + i + 1;
|
||||
}
|
||||
result = result ++ field.name[index..];
|
||||
break :blk result;
|
||||
};
|
||||
}
|
||||
|
||||
test flag_name {
|
||||
const field = @typeInfo(struct { statsd: bool }).Struct.fields[0];
|
||||
try std.testing.expectEqualStrings(flag_name(field), "--statsd");
|
||||
}
|
||||
|
||||
fn flag_name_positional(comptime field: std.builtin.Type.StructField) []const u8 {
|
||||
comptime assert(std.mem.indexOf(u8, field.name, "_") == null);
|
||||
return "<" ++ field.name ++ ">";
|
||||
}
|
||||
|
||||
/// This is essentially `field.default_value`, but with a useful type instead of `?*anyopaque`.
|
||||
pub fn default_value(comptime field: std.builtin.Type.StructField) ?field.type {
|
||||
return if (field.default_value) |default_opaque|
|
||||
@as(*const field.type, @ptrCast(@alignCast(default_opaque))).*
|
||||
else
|
||||
null;
|
||||
}
|
||||
|
||||
// CLI parsing makes a liberal use of `fatal`, so testing it within the process is impossible. We
|
||||
// test it out of process by:
|
||||
// - using Zig compiler to build this very file as an executable in a temporary directory,
|
||||
// - running the following main with various args and capturing stdout, stderr, and the exit code.
|
||||
// - asserting that the captured values are correct.
|
||||
pub const main = if (@import("root") != @This())
|
||||
// For production builds, don't include the main function.
|
||||
// This is `if __name__ == "__main__":` at comptime!
|
||||
{} else struct {
|
||||
const CliArgs = union(enum) {
|
||||
empty,
|
||||
prefix: struct {
|
||||
foo: u8 = 0,
|
||||
foo_bar: u8 = 0,
|
||||
opt: bool = false,
|
||||
option: bool = false,
|
||||
},
|
||||
pos: struct { flag: bool = false, positional: struct {
|
||||
p1: []const u8,
|
||||
p2: []const u8,
|
||||
p3: ?u32 = null,
|
||||
p4: ?u32 = null,
|
||||
} },
|
||||
required: struct {
|
||||
foo: u8,
|
||||
bar: u8,
|
||||
},
|
||||
values: struct {
|
||||
int: u32 = 0,
|
||||
size: ByteSize = .{ .value = 0 },
|
||||
boolean: bool = false,
|
||||
path: []const u8 = "not-set",
|
||||
optional: ?[]const u8 = null,
|
||||
choice: enum { marlowe, shakespeare } = .marlowe,
|
||||
},
|
||||
|
||||
pub const help =
|
||||
\\ flags-test-program [flags]
|
||||
\\
|
||||
;
|
||||
};
|
||||
|
||||
pub fn main() !void {
|
||||
var gpa_allocator = std.heap.GeneralPurposeAllocator(.{}){};
|
||||
const gpa = gpa_allocator.allocator();
|
||||
|
||||
var args = try std.process.argsWithAllocator(gpa);
|
||||
defer args.deinit();
|
||||
|
||||
const cli_args = parse(&args, CliArgs);
|
||||
|
||||
const stdout = std.io.getStdOut();
|
||||
const out_stream = stdout.writer();
|
||||
switch (cli_args) {
|
||||
.empty => try out_stream.print("empty\n", .{}),
|
||||
.prefix => |values| {
|
||||
try out_stream.print("foo: {}\n", .{values.foo});
|
||||
try out_stream.print("foo-bar: {}\n", .{values.foo_bar});
|
||||
try out_stream.print("opt: {}\n", .{values.opt});
|
||||
try out_stream.print("option: {}\n", .{values.option});
|
||||
},
|
||||
.pos => |values| {
|
||||
try out_stream.print("p1: {s}\n", .{values.positional.p1});
|
||||
try out_stream.print("p2: {s}\n", .{values.positional.p2});
|
||||
try out_stream.print("p3: {?}\n", .{values.positional.p3});
|
||||
try out_stream.print("p4: {?}\n", .{values.positional.p4});
|
||||
try out_stream.print("flag: {}\n", .{values.flag});
|
||||
},
|
||||
.required => |required| {
|
||||
try out_stream.print("foo: {}\n", .{required.foo});
|
||||
try out_stream.print("bar: {}\n", .{required.bar});
|
||||
},
|
||||
.values => |values| {
|
||||
try out_stream.print("int: {}\n", .{values.int});
|
||||
try out_stream.print("size: {}\n", .{values.size.bytes()});
|
||||
try out_stream.print("boolean: {}\n", .{values.boolean});
|
||||
try out_stream.print("path: {s}\n", .{values.path});
|
||||
try out_stream.print("optional: {?s}\n", .{values.optional});
|
||||
try out_stream.print("choice: {?s}\n", .{@tagName(values.choice)});
|
||||
},
|
||||
}
|
||||
}
|
||||
}.main;
|
||||
|
||||
// Note: I removed tests to not pull too many deps
|
||||
3
examples/tools/buildifier.sh
Executable file
3
examples/tools/buildifier.sh
Executable file
@ -0,0 +1,3 @@
|
||||
#!/bin/bash
|
||||
cd "$(dirname "${BASH_SOURCE[0]}")"
|
||||
exec bazel run -- @buildifier_prebuilt//:buildifier "$@"
|
||||
3
examples/tools/zig.sh
Executable file
3
examples/tools/zig.sh
Executable file
@ -0,0 +1,3 @@
|
||||
#!/bin/bash
|
||||
cd "$(dirname "${BASH_SOURCE[0]}")"
|
||||
exec bazel run --config=silent @zml//third_party/zls:zig -- "${@}"
|
||||
3
examples/tools/zls.sh
Executable file
3
examples/tools/zls.sh
Executable file
@ -0,0 +1,3 @@
|
||||
#!/bin/bash
|
||||
cd "$(dirname "${BASH_SOURCE[0]}")"
|
||||
exec bazel run --config=silent @zml//third_party/zls:zls -- "${@}"
|
||||
8
examples/zls.build.json
Normal file
8
examples/zls.build.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"build_options": [
|
||||
{
|
||||
"name": "cmd",
|
||||
"value": "bazel run @zml//zml:completion"
|
||||
}
|
||||
]
|
||||
}
|
||||
Loading…
Reference in New Issue
Block a user